Smart AI Model Load Balancing
Smart AI Model Load Balancing
Summary
Storytell now uses intelligent model selection instead of always choosing the same “best” AI model for every request. Our new probabilistic routing system distributes requests across the top-performing models, preventing overload on any single model while maintaining response quality. This results in faster response times and improved system reliability during peak usage.Who We Built This For
We built this for all Storytell users who interact with AI-powered features, especially power users and organizations with high-volume usage patterns. This particularly benefits users during peak hours when AI models experience heavy load, ensuring consistent performance and availability.The Problem We Solved With This Feature
Previously, Storytell’s routing system always selected the highest-scoring AI model, which meant one model received all traffic and could become overloaded. This created bottlenecks, slower response times, and potential service interruptions when the primary model was under heavy load or experiencing issues.Specific Items Shipped
- Probabilistic Model Selection: Implemented smart routing that selects from the top 3-5 highest-scoring models using weighted probability distribution rather than always picking the #1 model
- Load Distribution Algorithm: Created sophisticated scoring system that considers model quality, cost, and performance to distribute requests intelligently
- Enhanced Model Scoring: Added comprehensive model evaluation including new Gemini models and improved context window buffer calculations
- Dynamic Temperature Control: Implemented configurable temperature settings that control how random or deterministic model selection should be
- Top-K Filtering: Added ability to limit selection to only the highest-performing models while still distributing load among them
Explained Simply
Think of it like choosing which checkout line to use at a grocery store. Before, everyone always went to the “fastest” cashier, creating a huge line while other good cashiers stood empty. Now, our system is smart enough to send people to any of the top 3-4 fastest cashiers, spreading out the crowd so everyone gets served more quickly. The system still prefers the best cashiers, but it makes sure no single one gets overwhelmed while others sit idle.Technical Details
The implementation centers around a new ModelSelector class with configurable routing strategies (deterministic vs probabilistic). The probabilistic strategy uses softmax function with temperature scaling to convert model scores into selection probabilities. Key parameters include TopK filtering (default 5), temperature control (default 4.0), and minimum probability thresholds (5%). The system applies score transformation using configurable power functions to amplify differences between high and low-scoring models. Context window buffer calculations were enhanced to account for reasoning tokens and output tokens, with model-specific buffers ranging from 5K-20K tokens. The router maintains transparency by reordering results to show the selected model first while preserving all candidate information for debugging and analysis.Smarter Prompt Library with Enhanced Tabs and Favorites
Smarter Prompt Library with Enhanced Tabs and Favorites
Summary
A revamped Prompt Library experience lets you better organize, filter, and access prompts in Storytell. Tabs now make it simple to switch views between Favorites, My Prompts, Shared/Team Prompts, and All. You can also mark prompts as Favorites, making commonly used prompts quickly accessible. This update aims to reduce friction, speed up workflow, and make your prompt library feel personalized and efficient.Who We Built This For
This is designed for all Storytell users who save, reuse, or manage prompts—especially researchers, power users, and teams collaborating on prompt creation. It’s for anyone whose workflow speeds up by quickly accessing their go-to prompts or collaborating across teams by sharing prompt collections.- New tabs for Favorites, Personal, Shared, and All Prompts
- Mark or unmark prompts as Favorites and view them in a dedicated tab
- Prompt search and filtering improved across categories
- Visibility of Favorites on main screens and text selection widgets
Who We Built This For
This was requested by Berj and is designed for all Storytell users who save, reuse, or manage prompts—especially researchers, power users, and teams collaborating on prompt creation. It’s for anyone whose workflow speeds up by quickly accessing their go-to prompts or collaborating across teams by sharing prompt collections.The Problem We Solved With This Feature:
Before this release, users had a harder time navigating their collections of prompts, and finding “their” prompts from team ones was confusing. Favorites were not clearly organized, making high-use prompts harder to access. By introducing tabs and favorites, navigating and managing prompts is more intuitive and personalized.Specific Items Shipped:
- Prompt Library Tabs: Users can now browse by category: Favorites, Personal, Shared, or All Prompts for faster, more logical navigation.
- Mark as Favorite: Easily flag any prompt as a Favorite for instant access across the platform, including in the main prompt experience and selection widget.
- Improved Filtering and Sorting: Prompts can be filtered and sorted by name, description, or content, and Favorites are always surfaced at the top.
- Backend Support for Favorites: System updates support server-side “favorite” status for prompts, improving speed and reliability for personal and team libraries.
Explained Simply:
Think of the new Prompt Library like your streaming service playlists—now, you have clear tabs to jump to your Favorites, your own curated set, or see what your team has added. If you find a prompt really helpful, mark it as a Favorite, and it will always be just a click away. No more digging through a messy list—everything is sorted the way you want.Technical Details:
- Tabs implemented as filters tied to prompt metadata: “personal”, “favorites”, “shared”, “all”.
- “Favorite” status of each prompt is now a persistent field in the backend database, and prompt-related APIs updated to recognize and change this status.
- UI and API support expanded to handle new prompt-list queries by category, including dedicated endpoints for marking/unmarking favorites and fetching favorites quickly.
- The Prompt Library updates trigger reactive UI updates, keeping state in sync between client and server.
Human-Friendly, Actionable Streaming Error Messages
Human-Friendly, Actionable Streaming Error Messages
Summary
Streaming errors in SmartChats™ now give you clear, actionable feedback if something goes wrong while waiting for a response. Users get human-readable error messages that explain what happened and what to do next, rather than generic, confusing failures or silent timeouts.- Customized error messages for connection issues, network timeouts, and interrupted streams
- Helpful suggestions for retrying when appropriate
- Improved user understanding of what went wrong during streaming
Who We Built This For
Storytell users who rely on SmartChats™—especially those who need reliable, real-time answers and want to know why a SmartChat™ fails or disconnects.The Problem We Solved With This Feature:
Previously, when a streaming error occurred in SmartChats™, users might get a vague error, a raw code, or nothing at all. There was no clarity if the issue was on their side, the server, or if retrying might help. Now, errors are self-explanatory and guide users toward actions like retrying or checking their connection.Specific Items Shipped:
- User-Friendly Streaming Error Messages: Clear titles and explanations for specific errors (e.g., timeouts, connection lost, network problems).
- Retry Guidance: When an error is likely temporary, users are advised to try again and told how soon a retry is recommended.
- Meaningful Error Codes & Tips: Error codes are mapped to descriptive text and, where possible, provide additional troubleshooting details.
- Streaming System Resilience: Even on unexpected errors, Storytell recovers gracefully and tells the user what happened.
Explained Simply:
If you were on a phone call and the call dropped, wouldn’t you want to know whether to hang up, call back, or just wait? Storytell now tells you, in plain English, what went wrong if an answer can’t be delivered—and suggests what to do next—so you aren’t left guessing.Technical Details:
- Extended error handling and classification in the streaming and SSE (Server-Sent Events) service.
- All error events are mapped to user-friendly messages via a client-side error mapping object and surfaced in the UI.
- Specific error codes (timeout, network issue, permission, resource limit, parsing error) now produce actionable messages, e.g., “Connection issue. Please try again.”
- The stream processor now handles, logs, and relays error responses and decodes them for clear client presentation.
- Reconnection and retry timing guidance is also included for transient errors.
Gemini 2.5 Model Upgrade
Gemini 2.5 Model Upgrade
Summary
Storytell has upgraded from Gemini 2.0 Flash to Gemini 2.5 Flash across all AI models to improve performance and reliability. The newer Gemini 2.5 models offer enhanced internal capacity, better error handling, and increased output token limits to accommodate the models’ advanced thinking capabilities. This upgrade includes Gemini 2.5 Flash, Gemini 2.5 Flash Thinking, and Gemini 2.5 Pro models with significantly higher maximum output token limits (from 8,192-32,768 to 64,512 tokens).Who We Built This For
Users experiencing performance issues, truncated responses, or capacity errors when working with complex documents or requesting detailed analyses. This particularly benefits power users who need comprehensive responses and organizations processing large volumes of content.The Problem We Solved With This Feature
We solved performance degradation and truncated output issues caused by the previous Gemini 2.0 models. Google experts recommended this migration because Gemini 2.5 models have more internal capacity, handle errors better, and accommodate the increased thinking token consumption that was causing latency issues and output truncation.Specific Items Shipped
• Gemini 2.5 Flash migration: Upgraded the primary model from Gemini 2.0 Flash to Gemini 2.5 Flash for improved performance and reliability across all content processing• Enhanced output token limits: Increased maximum output tokens from 32,768 to 64,512 for Gemini 2.5 Flash models and from 8,192 to 64,512 for Gemini 2.5 Pro to prevent response truncation• Thinking mode optimization: Updated token allocation to accommodate the increased thinking token consumption in Gemini 2.5 models, reducing latency and truncation issues• Model specification updates: Updated all model specifications across the platform to use the new Gemini 2.5 variants with optimized settingsExplained Simply
Think of AI models like different versions of a smart assistant. We upgraded from version 2.0 to version 2.5 because the newer version is more reliable and can handle bigger, more complex tasks without getting overwhelmed. The old version sometimes got “tired” and would cut off its answers halfway through, especially when thinking hard about difficult questions. The new version has more “brain power” and stamina, so it can give you complete, thoughtful answers even for the most challenging requests.Technical Details
The implementation involved updating model specifications in pkg/go/domains/ai/spec.go for GoogleGemini25FlashThinkingSpec, GoogleGemini25FlashSpec, and GoogleGemini25ProSpec. MaxOutputTokens were increased to 64,512 across all Gemini 2.5 models based on Google’s recommendation to accommodate increased thinking token consumption. The migration also updated the default model specification in the extractor from ai.GoogleGemini20Flash to ai.GoogleGemini25Flash. Context windows remained at 550,000 tokens, and all models maintain streaming capabilities with 2-minute maximum response times.File Processing Status Notifications
File Processing Status Notifications
Summary
Storytell now informs users when uploaded files are still being processed and may not be included in AI responses. A clear notification system displays processing status and file counts, ensuring users understand when their analysis might be incomplete due to ongoing file ingestion.Who We Built This For
This feature was built for users who frequently upload files for analysis, particularly customers like Jessica, Nicholas, Stephen, Flavio, and other power users who need to know when their uploaded content is ready for analysis. It addresses feedback from users who were frustrated when AI responses didn’t include recently uploaded files.The Problem We Solved With This Feature
We solved the confusion and frustration users experienced when AI responses seemed incomplete or didn’t reference recently uploaded files. Users had no way of knowing whether their files were still processing, leading to questions about why certain content wasn’t being analyzed. This lack of transparency created uncertainty about when files would be ready and whether responses were comprehensive.Specific Items Shipped:
• Processing Status Indicator: Added a notification bar that appears when files are still being processed, showing users exactly how many files are currently being ingested.• Dynamic File Count Display: Implemented real-time tracking that shows “1 file is processing” or “X files are processing” based on the actual number of files in processing state.• Visual Processing Feedback: Created a spinner icon and clear messaging that informs users their analysis may be incomplete while files are still being processed.• Intelligent State Management: Built logic to determine processing state based on lifecycle status and modification timestamps, ensuring accurate processing indicators.Explained Simply
Imagine you’re at a copy shop and you hand over a stack of documents to be scanned. Before this feature, it was like the worker taking your documents and you having no idea if they were still scanning them or if they were done. Now, it’s like having a status board that shows “Still scanning 3 documents” so you know to wait before asking for your analysis. This way, you won’t wonder why your results seem incomplete - you’ll know exactly when everything is ready.Technical Details
The implementation uses SolidJS reactivity with createMemo() to track processing assets in real-time. The readableProcessingState() function evaluates asset lifecycle states and modification timestamps to determine if files are still being processed. The notification system integrates with the ChatTopBar component, displaying a tooltip with spinner animation when processingAssets?.() > 0. The feature includes proper state management through rawProps.processingAssets?.() accessor that provides accurate counts of assets in processing state. Visual feedback is implemented through conditional rendering with appropriate styling and responsive text that handles both singular and plural file counts.Enhanced Text Selection Menu with Disable Option
Enhanced Text Selection Menu with Disable Option
50-Message Limit for SmartChats™
50-Message Limit for SmartChats™
Summary
We’ve implemented a comprehensive message limit system that caps SmartChats™ at 50 messages per thread. When users reach this limit, the prompt bar becomes disabled, they see a clear notification explaining the limit, and they’re guided to start a new chat to continue their conversation. This applies to both frontend interactions and backend processing to ensure system stability.Who We Built This For
All Storytell users who engage in extended conversations through SmartChats™. This particularly benefits power users who tend to have very long conversations, as it prevents system performance issues while guiding them toward more effective conversation management.The Problem We Solved With This Feature
We solved the problem of system performance degradation and potential stability issues caused by extremely long SmartChat™ threads. Very long conversations can consume excessive resources and negatively impact the user experience. By implementing this limit, we maintain optimal performance while encouraging users to start fresh conversations when appropriate.Specific Items Shipped:
• Frontend message limit enforcement: The prompt bar becomes disabled and uneditable when message count exceeds 50, with visual indicators showing the limit has been reached• Clear user notification system: Users see “Limit of 50 messages per thread reached. Start a new chat to continue” message in the chat interface• Backend message validation: Server-side validation prevents processing of new messages when thread exceeds 50 messages, returning appropriate error responses• Keyboard shortcut protection: All keyboard shortcuts for sending messages (Mod-Enter, Enter, Shift-Enter) are disabled when the limit is reachedExplained Simply
Think of SmartChats™ like a notebook where you have conversations with an AI assistant. Just like how a physical notebook has a limited number of pages, we’ve set a limit of 50 messages per conversation to keep things running smoothly. When you hit that limit, the notebook is “full” and you need to start a new one. You’ll see a clear message telling you this happened, and your input box will be grayed out so you know you can’t add more to that conversation. It’s like when your phone tells you the storage is full - you need to start fresh to keep everything working well.Technical Details
The implementation uses a constant MESSAGE_LIMIT = 50 shared between frontend and backend. Frontend enforcement includes reactive computations using createMemo() to track message count, conditional editor disabling through editor.setEditable(), and visual state changes including disabled button styling and tooltip messages. The chat send button becomes disabled with red styling and shows explanatory tooltips. Backend validation occurs in the ReceiveMessage handler, checking len(aggregate.State().Messages) > maxMessagePerThread and returning ErrTooManyMessages error. Keyboard shortcuts are intercepted in the ChatSettingsExtension with isMessageLimitReached() checks that prevent all submission methods. The system maintains consistency between client and server validation to ensure robust enforcement.Collection Auto-Expansion in Sidebar
Collection Auto-Expansion in Sidebar
Improved Handling for Empty Knowledge Base Searches
Improved Handling for Empty Knowledge Base Searches
Summary
Storytell now provides clear, helpful guidance when a user attempts to search a knowledge base with no matching results. Instead of showing generic errors or generating citations for non-existent references, the system delivers a friendly, informative message explaining potential causes and next steps. This enhancement prevents confusion and helps users troubleshoot common issues when working with knowledge-scoped prompts.Who We Built This For
This feature was built for all Storytell users who use knowledge base scoping in their prompts, especially those working with Collections that may be newly created, still processing uploads, or have specific content limitations that could result in zero search results.The Problem We Solved With This Feature:
Previously, when users issued prompts scoped to their knowledge base but no relevant documents were found, the system would either generate generic errors or, worse, create responses with fabricated citations. This led to confusion and potentially misleading information. Users had no clear indication of why their knowledge-scoped queries weren’t working as expected, causing frustration and reducing trust in the system.Specific Items Shipped:
- Clear Feedback Messages: When no search results are found in the knowledge base, users now receive a specific, informative message explaining possible causes and suggesting next steps.
- Graceful Error Handling: The system now recognizes the “no search results” condition as a distinct scenario that requires user guidance rather than treating it as a general error.
- Improved Progress Messages: Enhanced progress message system now supports displaying messages without percentage indicators when appropriate, creating a cleaner, more helpful user experience.
Explained Simply:
Imagine asking a librarian to find books about a specific topic in a particular section of the library. If that section is empty or doesn’t contain any books on your topic, you’d want the librarian to tell you directly that they couldn’t find anything - and maybe suggest why (perhaps you’re in the wrong section, or the books are still being cataloged). That’s exactly what this feature does - instead of giving you a confusing error message or making up fake book references, Storytell now clearly tells you it couldn’t find any relevant information in your knowledge base and suggests possible reasons why, like being in the wrong Collection or having files that are still processing.Technical Details:
The implementation involved several components across the system:- A new error type ErrNoSearchResults was added to specifically identify when no search results are available from the knowledge base
- The prompt initialization process was enhanced to check if there are no search results and no attachments, returning the new error in that scenario.
- When no search results are found, the system displays a user-friendly message and gracefully terminates processing
- A new progress message specifically for no search results scenarios explains possible causes and next steps The progress message system was extended with:
- Support for “noTicks” option to display messages without percentage indicators
- A withNoTicks() option function for progress messages
- The prompt builder was updated to handle the special error case and ensure the message is always properly delivered to the UI, avoiding race conditions that could prevent the message from displaying.
- All messages now properly include closing tags to prevent UI freezing issues.
SmartChat™ Auto-Scrolling
SmartChat™ Auto-Scrolling
Summary
We’ve refined the auto-scrolling behavior in SmartChats™ within Storytell. This update ensures that as new messages arrive, the view smoothly and reliably moves to the latest content, making it easier to follow active discussions without losing your place or missing new information.- Reliable scrolling to new messages.
- Smoother scroll animations.
- Improved focus on the latest part of the conversation.
Who We Built This For
This enhancement is for all Storytell users who actively engage with SmartChats™, especially those involved in longer or rapidly evolving conversations. It benefits users who need to stay current with real-time responses and those who might be multitasking and rely on the interface to keep them oriented to the newest message.The Problem We Solved With This Feature
Previously, the auto-scrolling in SmartChats™ could sometimes be inconsistent. Users might have experienced the view not correctly jumping to the latest message, or the scroll movement might have felt abrupt. This could lead to confusion, missed messages, or a less fluid user experience when trying to follow a dynamic conversation. This update addresses these inconsistencies to provide a more seamless and reliable interaction.Specific Items Shipped
- Implemented a new
useThreadAutoScrollhook: This custom hook centralizes the logic for auto-scrolling within SmartChats™. It ensures consistent behavior whenever new messages are received and rendered. - Introduced event-driven scrolling: Storytell now uses a custom event (
threadResponseReceived) dispatched after a message is fully rendered. This replaces previous timeout-based mechanisms, making the scroll trigger more precise and avoiding issues where scrolling occurred before content was ready. - Refined scroll animation and targeting: The scroll action now uses the browser’s native
scrollTomethod with thebehavior: 'smooth'option. It targets the full scroll height of the SmartChat™ container, ensuring the latest message is always brought into view gracefully. - Optimized scroll timing with
requestAnimationFrame: We utilize a doublerequestAnimationFramecall before initiating the scroll. This ensures that all DOM updates and layout calculations related to the new message are completed by the browser, leading to more accurate and stable scrolling.
Explained Simply
Imagine you’re having a text message conversation on your phone that’s getting lots of replies quickly. Before, Storytell’s SmartChat™ might have sometimes been a bit clumsy in showing you the newest message – maybe it didn’t scroll down all the way, or it jumped suddenly. We’ve now made it much smarter and smoother. Think of it like your phone’s messaging app perfectly gliding down to each new text as it arrives, so you can easily keep up with the chat without any weird jumps or having to manually scroll all the time. It just works better, making your conversations in Storytell feel more natural.Technical Details
The implementation introduces a new useThreadAutoScroll hook that manages scroll behavior through custom events. When a new message is received, a threadResponseReceived event is dispatched through the custom events system. The hook uses double requestAnimationFrame calls to ensure DOM updates are complete before scrolling, preventing race conditions with message rendering.The scroll behavior is implemented using the scrollTo API with smooth scrolling, targeting the container’s full scroll height. The system is integrated at the thread machine level, which dispatches events only for text-based messages, ensuring appropriate timing with message processing and rendering.Key technical changes include:Removal of manual timeout-based scrolling in favor of event-driven approach Implementation of custom event system for thread responses Integration with main content container through global element IDs Cleanup of scroll-related refs and margin handling Event listener cleanup through SolidJS cleanup systemInline Citations
Inline Citations
Summary
Storytell now includes inline citations in its answers, giving users the ability to verify exactly which part of their source material was used. This update ensures clarity and trust, making it easy to track the origin of any information shown in SmartChat™ and other responses.Key updates:- Inline citations now appear in every response, providing a clear reference to the source material used.
- Users can easily verify the source of any information shown in SmartChat™ and other responses.
- This update ensures clarity and trust, making it easy to track the origin of any information shown in SmartChat™ and other responses.
Who We Built This For
This feature was built for all Storytell users, particularly those who need to validate the accuracy and origin of AI-generated information. It directly addresses users like James, Berj, Cheryl, Tiyale, Kelly, Stephen, Aisha, Juliet, and many more who previously expressed uncertainty about whether Storytell’s answers were derived from his uploaded data.The Problem We Solved With This Feature:
Users had no way to verify whether an answer truly came from their data or public knowledge. The lack of transparency risked trust in Storytell’s responses.Specific Items Shipped:
- Inline Citation Tagging: Citations are embedded within answers, using distinct tags that link to source material.
- Clickable Citation Numbers: Users can click citation numbers in responses, opening a panel that directly displays the original data snippet or asset section referenced.
- Citation Panel Display: A side panel shows the context and details for each citation, including formatting improved for readability.
Explained Simply:
It’s like when you read an online article with footnotes—if you see a[1] or [2] in the sentence, you can click it to jump right to the source. Now, Storytell works the same way: when you get an answer, you can see exactly where every piece of information came from, and check the real text or file it was based on.Technical Details:
The system generates<citation> tags wrapped around claims that are supported by user data during answer generation.
On the frontend, citation numbers are mapped to these IDs, allowing for click-to-view source context in a citation panel/drawer.
The citation panel retrieves and formats the relevant data chunk from the user’s assets for display.- Citation panel includes navigation, error handling for missing assets, and markdown rendering improvements for citations and extracts.
- Backend logic constrains the number of citations shown and ensures only relevant matches are displayed; frontend disables citation controls for unsupported models.
Citation-Compatible Models
Citation-Compatible Models
Summary
Storytell now ensures that only large language models (LLMs) capable of processing citations are enabled when users require citations in their results. This update makes the citation experience more reliable, as it avoids models that can’t accurately provide references or properly handle source citations. Users no longer need to guess whether a model supports citations—the system automatically prioritizes and enables models with citation abilities when knowledge base interactions or citations are required.Key updates:- Only citation-compatible models are selectable when citations are needed
- System prioritizes higher quality models for user prompts
- The Citations button is automatically disabled if a model doesn’t support citations
Who We Built This For
This feature is designed for all users who rely on Storytell for accurate, reference-based answers. In particular, it solves issues for users in compliance-sensitive, research-driven, or analytical workflows where verifying information sources is essential.The Problem We Solved With This Feature:
Previously, some models that users could select didn’t properly support citations, resulting in incomplete or faulty references. This created confusion and undermined the trust in answers, especially in scenarios where source traceability was necessary.Specific Items Shipped:
- Citation Capability Detection: Only models with built-in citation functionality are presented to users when citation features are toggled on or required by a prompt.
- Automatic Citation Button Disabling: The Citations UI button is disabled for models that do not support citations, preventing users from attempting to activate citation features with incompatible models.
- Model Prioritization: The system prioritizes higher-quality models for knowledge-base questions, making it easier for users (even with poorly-written prompts) to get better, trustworthy results.
- Enhanced Model Routing: Citation support is now a core capability tracked and used in routing models for each prompt.
Explained Simply:
Imagine you’re asking Storytell for an answer and you want to know exactly where that answer came from, like a bibliography in a research paper. Previously, some “helpful friends” (models) would guess answers without being able to show their sources. Now, Storytell only lets you pick friends who actually do their homework and show you the exact book or website they used. If a friend can’t do that, the system lets you know and won’t let you rely on them for citations.Technical Details:
- Model capability definitions now include a ‘citations’ capability flag.
- The model selection logic filters out models that don’t support citations whenever a citation-enabled workflow is in use.
- When a citation-incompatible model is selected, the Citations button in the UI is visually disabled, ensuring the user is aware of the limitation.
- The router is updated to select the “better” (higher-quality, higher-reasoning) models first when citations are required, improving answer quality by default.
- These changes required updates to both backend logic (model capability checks) and frontend components handling model selection and citation UI state.
Claude 4 Sonnet Integration
Claude 4 Sonnet Integration
Summary
A new advanced model, Claude 4 Sonnet, is now available in Storytell. This release expands the conversational AI capabilities by adding both the Claude 4 Sonnet and the Claude 4 Sonnet Thinking models. These models offer improved reasoning and context handling for SmartChats™, providing users with more accurate and context-aware AI responses. Users can now select these models in both the chat prompt and action bars, giving them better control over their AI experience. This update keeps Storytell at the forefront of AI capabilities, addressing user requests for the latest generation language models.Key updates:- Introduced Claude 4 Sonnet and Claude 4 Sonnet Thinking to the model selection menus.
- Enhanced support for large context windows (up to 180,000 tokens).
- Improved future readiness by scaffolding for richer model ranking and capability metadata.
Who We Built This For
This feature was designed for power users, enterprise teams, and organizations using SmartChats™ within Storytell who want access to the latest, high-performance AI models. It is particularly beneficial for researchers, analysts, and knowledge workers who need accurate, high-context responses for complex prompts, as well as for any user who wants to experiment with the newest AI options available.The Problem We Solved With This Feature:
Prior to this release, users did not have access to Anthropic’s latest Claude 4 series models inside Storytell, limiting both the depth and breadth of high-level conversational generation they could perform. This restricted complex use cases where large context windows, advanced reasoning capabilities, and state-of-the-art generation are necessary. By introducing Claude 4 Sonnet, we’re enabling deeper research, complex task automation, and more flexible conversations within SmartChats™.Specific Items Shipped:
-
Claude 4 Sonnet and Claude 4 Sonnet Thinking Models Added:
Both new Anthropic models (standard and “Thinking” flavor) are now selectable in the Storytell chat interface, giving users more options for generating high-quality, context-rich responses. -
UI Enhancements in Model Selection:
Users can now pick Claude 4 Sonnet or Claude 4 Sonnet Thinking directly from model menus in both the chat prompt (“ChatBottomBar”) and SmartChats™ action bars, improving accessibility and control during workflow. -
Extended Context Window (180k Tokens):
The new models are configured with an extended 180,000 token context window, allowing substantially longer conversations and prompt/response chains before context is lost. -
Backend Model Specification Updates:
Full specifications, cost mappings, and meta information were added to the backend. This lays groundwork for benchmarking and more granular model analytics in the future. -
Disabled by Default Pending Rollout:
While full scaffolding exists, these models are marked as disabled by default in preparation for controlled rollout.
Explained Simply:
Imagine having a super-smart assistant who remembers most of your conversation—not just the last sentence or two—and can give you really thoughtful advice, even on huge topics. By adding Claude 4 Sonnet to Storytell, you now have access to that kind of helper. It’s like getting a new, upgraded calculator that can also talk to you and help you think through problems—especially if they’re long and complicated. Now, whenever you’re chatting or working on projects in Storytell, you can pick this new assistant to help you get better answers without losing track of the conversation.Technical Details:
-
Model Integration:
Two new models,anthropic-claude-4-sonnetandanthropic-claude-4-sonnet-thinking, were introduced as selectable Model entries. Each model is assigned its own metadata, including display name, vendor, provider, family tag, ranking scaffold, and capabilities. -
Cost Configuration:
Pricing for prompt and completion tokens (3.00 per 1M input tokens, 15.00 per 1M output tokens) was set to align with other Claude Sonnet variants, ensuring consistent cost calculation across all models. -
Spec Definition:
Each model comes with aModelSpecconfiguration that specifies context window size (180_000tokens), max output tokens (8_192), streaming support, and max response time (2 min). All ranking and capability fields are pre-populated or stubbed for future metric updates. -
Frontend Integration:
The UI’s model selection areas (in bothChatBottomBar.tsxandTextUnitV1ActionsBar.tsx) were updated to add menu items for Claude 4 Sonnet and Claude 4 Sonnet Thinking, each with proper iconography and selection logic, ensuring a clear highlight on active selection. -
API and Client Library Regeneration:
TypeScript client code was regenerated (ai.gen.ts,models.gen.ts) to include the new models and their associated typings, ensuring strongly typed access throughout the app. -
Rollout Status:
Both models are currently marked as disabled pending broader rollout, allowing feature-flagged or admin enablement before universal availability.
Regenerate Button for Every Response
Regenerate Button for Every Response
Chrome Extension Text Selection Pop-Up
Chrome Extension Text Selection Pop-Up
Summary
The Chrome Extension has been enhanced to support instant interaction with selected text on any web page. When you highlight text in the browser, a SmartPop-up now appears, offering one-click options to summarize, highlight takeaways, or start a SmartChat™ using that exact passage. This enables powerful, context-aware AI use cases far beyond basic copy-paste.Key updates:- Pop-up menu appears automatically when text is highlighted in Chrome with the Storytell extension installed.
- Choose from pre-built prompt actions or open a SmartChat™ directly with the selected passage.
- Feature toggle in settings allows users to turn this behavior on or off at will.
Who We Built This For
This feature was designed for story editors, researchers, journalists, students, and anyone using Storytell in Chrome who finds themselves wanting instant analysis, summary, or AI chat regarding specific passages encountered online. It streamlines workflows for those who work with online content and need rapid, insightful engagement with source material.The Problem We Solved With This Feature:
Previously, if you wanted to analyze or discuss a piece of text on the web with Storytell, you had to manually copy it, open the extension, and paste it in. This slowed down research, learning, and content review cycles. With the new SmartPop-up, users can take immediate AI action on any highlighted passage, making the process nearly instant.Specific Items Shipped:
-
Automatic Pop-Up on Text Selection
When users highlight any text in Chrome (with the extension installed), a contextual menu appears offering tailored AI actions. -
One-Click SmartChat™ Initiation
Start a conversation or run a summary on highlighted text directly, without manual copy-paste. -
Pre-Built Prompts for Fast Actions
Menu options include actions like “Summarize this content” and “Highlight the most important takeaways,” with executive-focused and bullet-pointed outputs. -
Theme-Aware UI and Settings Toggle
Pop-up supports both dark/light mode and can be turned off or on via the extension’s settings. -
Frozen Attachment Storage
Selected text is frozen and stored as an immutable attachment in the new SmartChat™, ensuring context is preserved.
Explained Simply:
Think of the new feature as a supercharged highlighter. When you mark a sentence or paragraph in your web browser, instead of just leaving it yellow, the Chrome Extension pops up and asks: “Want me to summarize this? Or start a chat about it?” It’s instant—just highlight and choose what you want. You get executive summaries, lists of main points, or can even kick off a discussion, all without having to leave the page, copy, or paste.Technical Details:
- Content script (text-selection.content.tsx) injects a floating UI using @floating-ui for precise pop-up positioning on text selection.
- On text selection and mouseup, it creates an off-screen anchor div at the selection bounds.
- Pop-up menu renders within a shadow DOM for UI isolation, with theme auto-detection (dark/light).
- Menu actions send extension events (type: “extension.textSelectionCmd”) to the background script, which opens or focuses the sidepanel as required.
- Predefined prompt payloads (“Summarize this content”, “Highlight the most important takeaways”) are included in the event, which then triggers SmartChat™ creation and attaches/freeze the selection as reference.
- The extension uses IndexedDB to persist and freeze selected text for each SmartChat™, so attachments remain immutable even if the original page changes.
- Feature enable/disable state is stored in extension local storage and watched by the popup UI and settings.
Simplified New User Experience & Onboarding for Storytell
Simplified New User Experience & Onboarding for Storytell
Summary
New users of Storytell will now see a cleaner, more focused interface—removing the sidebar, Collections features, and most advanced tools until users are ready to engage with them. The onboarding flow has been redesigned to reduce distractions and help new users quickly upload their first asset or start a SmartChat™. Key elements such as mentions, slash commands, and Collection management are hidden for true newcomers, with onboarding links and helpful prompt suggestions highlighted front-and-center. This change ensures a more intuitive, frustration-free first interaction with Storytell. Read more about this update here.Key updates:- Simplified dashboard and workspace for new users without Collections or SmartChats™.
- Sidebar and advanced Collection actions are hidden until the user engages with core features.
- Direct onboarding documentation and links prominently displayed.
- User interface adapts automatically as users engage with Storytell.
Who We Built This For
- New users and first-time visitors to Storytell: The changes are primarily for users who have just created their Storytell account, have no Collections, and are getting started with SmartChats™.
- Users who want a clutter-free, approachable interface: Particularly those who may be intimidated or confused by complex toolsets being visible before they’re needed.
The Problem We Solved With This Feature:
Onboarding previously exposed all of Storytell’s advanced features—Collections, sidebar, mentions, and more—even to users with no prior experience. This caused unnecessary confusion and sometimes overwhelmed new users, leaving them unsure how to start. The updated experience aims to remove those roadblocks by stripping back optional features, focusing on a minimal, self-explanatory workspace with very clear next steps (like uploading an asset or starting a SmartChat™). This smooths the learning curve, ensuring users can begin using Storytell productively and confidently from their first session.Specific Items Shipped:
New Features-
Conditional Sidebar & Feature Visibility:
Storytell now automatically hides the sidebar and all Collection-related features for accounts with no Collections and no SmartChats™. The advanced UI will only appear once the user begins engaging (uploads an asset, starts a SmartChat™, or is invited to a Collection). -
Streamlined Onboarding Welcome Screen:
The welcome screen for new users shows only essential instructions with a prompt bar, onboarding link (“Learn how”), and a clear message:
“Welcome to Storytell. Add an asset to start chatting with it. [Learn how].” -
Context-Aware UI for Returning Users:
Returning users who have SmartChats™ but no Collections will see recent chats and a minimal interface, avoiding interruption with Collection prompts. -
Direct Onboarding Documentation:
A “Learn how” link is provided on the welcome screen, opening onboarding documentation in a new tab to assist users with setup. -
Hiding Advanced Tools Until Needed:
Mentions, slash commands, and Collection creation tools are not shown until after a user becomes more advanced, ensuring the UI remains approachable.
- Not applicable (per reference, all changes are feature/UX improvements).
Explained Simply:
Imagine you just downloaded an app and, the moment you opened it, it threw up every option and button it had. You wouldn’t know where to start, right? Storytell used to do that—show everything, even the stuff you didn’t need yet. Now, it acts more like a good teacher: if it’s your first time here, you only see what you actually need, like a big welcome message and a single box to get started. When you upload something or start a SmartChat™, more features unlock as you go. Basically, the simpler layout means you’re not overwhelmed—you get to try Storytell without the stress of figuring everything out at once.Technical Details:
-
Conditional Rendering Based on User State:
The codebase introduces a new custom hook,useIsUserGettingStarted, to determine whether the user is in the onboarding/empty state. It checks if the user has any root Collections (that themselves have children) or any SmartChats™ (threads). If not, the UI enters onboarding mode. -
Sidebar and Collection Feature Hiding:
Components such asTwoColumnLayout,SideBarCollection, andCollectionsTophave been refactored. They now take props (hideSidebar,showLogo) that depend on the onboarding state, conditionally rendering those UI elements. -
Onboarding Welcome Screen Implementation:
The welcome UI uses an updatedCollectionGettingStartedScreencomponent with a clean scaffold: prominent message + upload/asset prompts + “Learn how” link (which opens the documentation at https://docs.storytell.ai/quickstart). -
Decommissioned Manual State Management:
The old state variablegettingStartedScreenManuallyHiddenhas been fully removed, as the onboarding screen is now determined automatically by the user’s data. -
Prompt Bar & Feature Button Adjustments:
In the chat UI (ChatTopBar.tsx,ChatBottomBar.tsx), toolbar buttons for advanced actions (like slash commands, uploads, mentions) only appear after the onboarding barrier is crossed. -
Styling Tweaks:
Margin and layout changes applied to onboarding screen components for improved clarity and spacing. -
No Bug Fixes Included:
All code changes represent feature development or refactoring directly supporting the onboarding improvement.
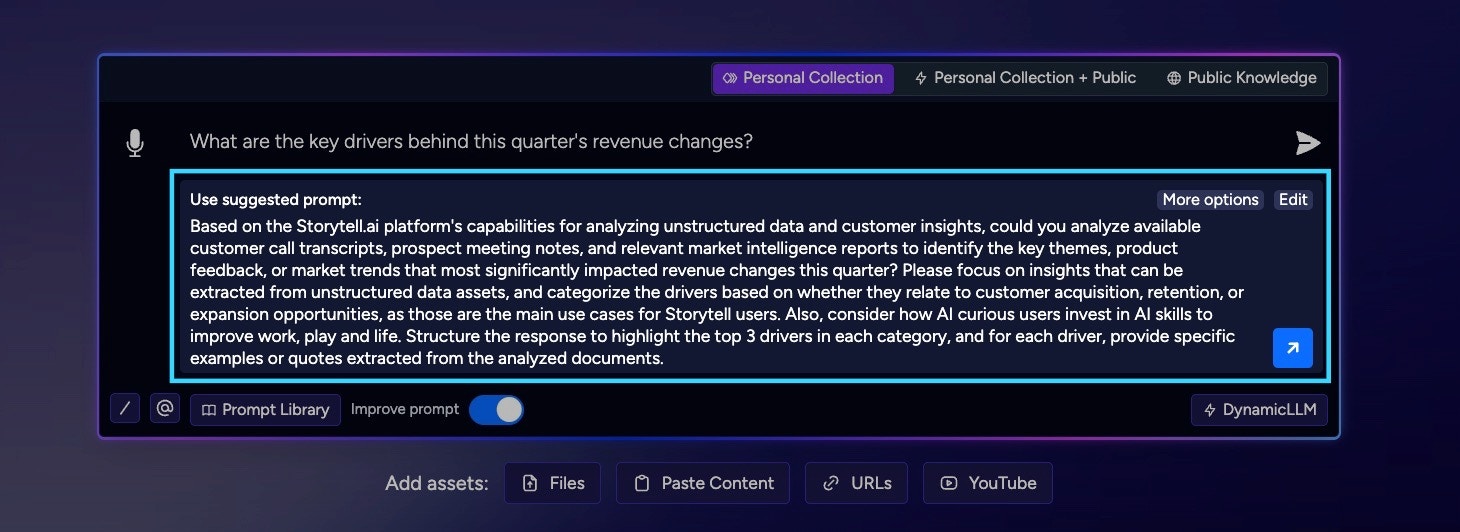
Dedicated Auto-Improve Prompt Section
Dedicated Auto-Improve Prompt Section
Summary
Storytell has launched a redesigned “Auto-Improve Prompt” feature that makes it quicker and easier for users to see and use improved prompt suggestions. The auto-improve functionality now appears in its own clearly defined area, making the suggested prompt modifications much more noticeable and accessible. Key improvements include a one-click send button, better editing options, and enhanced usability controls. This streamlines the workflow and reduces unnecessary steps, helping users create clearer questions and receive better answers more efficiently.Key updates:- Auto-improve suggestions now live in a dedicated section, no longer crowding the main chat area.
- Users can instantly send Storytell’s improved prompt with a new, prominent send button.
- Clear “Edit” action allows users to modify suggestions before sending.
- Auto-improve feature visibility is easy to control, so users can turn it on or off at any time.
- The overall prompt experience is visually clearer and easier to navigate.
Who We Built This For
This update primarily benefits prompt-writers, SmartChat™ users who are looking to fine-tune their questions or get the most accurate and helpful responses from Storytell. It’s especially valuable for users iterating on complex queries, those experimenting with different question phrasing, and new users who may need extra guidance in crafting effective prompts.The Problem We Solved With This Feature:
Previously, the auto-improve suggestion was less visible and could push essential controls (like the send button) out of the way, creating a clunky experience. Users had to make extra clicks to apply suggestions, causing workflow interruptions and friction. By isolating the auto-improve area and streamlining sending/editing actions, Storytell eliminates these annoyances — making it faster to see, accept, or adjust improved prompts. This matters because good prompts unlock better outcomes, and reducing friction leads to clearer questions and more accurate answers.Specific Items Shipped:
-
Dedicated Auto-Improve Section:
Auto-improve prompt suggestions display in a separate, visually distinct area. This prevents interference with the main chat and send controls. -
One-Click Send Button:
A new send button allows users to submit Storytell’s improved prompt immediately from the dedicated section, streamlining the process. -
Explicit “Edit” Option:
The “Apply” action was renamed to “Edit,” clarifying that users can tweak the improved suggestion before sending. -
Improved Visibility Controls:
Users can now toggle the auto-improve feature on or off for a tailored experience. When it’s on, Storytell’s suggestions are clearly highlighted. -
Cleaner Interface:
Visual feedback was improved, including removing underlining on hover, to reduce clutter and make navigation more intuitive. -
Technical Improvements:
Under-the-hood refactors moved the auto-improve logic into its own module/component, paving the way for future enhancements and maintainability.
Explained Simply:
Imagine you’re texting a friend, but your app quietly suggests a better way to say something — and the suggestion pops up helpfully where you can see it, without blocking your send button or making things harder. Now, if you like the suggestion, you can hit send right away, or you can choose to tweak what it wrote with a quick “Edit.” You can also turn these suggestions off if you don’t need them. It’s like having a smart assistant in your messaging app who helps you phrase things better, but lets you stay in control and never gets in your way.Technical Details:
-
Component Refactor:
The PromptAutoImprove component was reworked and moved into its own section within the main chat prompt codebase. This entailed adding new imports (StIcon,TbArrowUpRight), restructuring logic and JSX so that auto-improve is both visually and functionally isolated from the main smart chat prompt flow. -
UI/UX Adjustments:
- The dedicated auto-improve area now includes a clear “send” button, styled distinctively for prominence (
rounded bg-primary text-on-primary flex items-center). - The prior “Apply” text was replaced with “Edit” for the user action button.
- The send button now directly calls the
submitPromptfunction if the improved suggestion is available. - Removed legacy hover underline states for cleaner presentation.
- The dedicated auto-improve area now includes a clear “send” button, styled distinctively for prominence (
-
Workflow Logic:
- When a user clicks send in the auto-improve area, Storytell checks if there is improved content and submits it with empty mentioned assets.
- The new layout prevents the improved prompt from interfering with other chat controls.
- There are now explicit controls to open/close or toggle the auto-improve section.
-
Code Organization:
- Imports and props for relevant modules were adjusted, including icons and UI state handlers.
- Logic for handling prompt text, asset mentions, and collection mentions was preserved in the new layout.
- No changes to SmartChat™ storage or Collections handling logic were needed for this iteration.
Improved Mentions with Space Support and Enhanced UX
Improved Mentions with Space Support and Enhanced UX
Summary
The mentions feature in Storytell has been completely overhauled to provide a smoother, more intuitive experience. Now, mentioning assets or collections using ”@” supports entries that include spaces, and the interactive popup selector has been upgraded for better usability and reliability. This results in more accurate, user-friendly referencing within SmartChats™ and content, with faster keyboard navigation and clearer layouts.Key updates:- Mentions now work seamlessly with entries containing spaces.
- The suggestion popup behaves more predictably and no longer becomes stuck.
- Navigation and readability have been improved for quicker, error-free mention selection.
Who We Built This For
This update is designed for all Storytell users who reference assets or Collections within SmartChats™ or collaborative documents. It’s especially valuable for those working in teams who frequently mention specific resources, or who need a reliable way to tag assets with complex or multi-word names.The Problem We Solved With This Feature:
Previously, the mentions feature in Storytell struggled with names or labels that included spaces, leading to incomplete or incorrect tagging. Users also ran into interface bugs, such as a mention popup that wouldn’t disappear, and faced clunky navigation when selecting an item from suggestions. This made it frustrating to quickly and accurately reference Collections or assets in conversation, slowing down workflows and reducing confidence in the feature.By redesigning the mentions interaction, this update allows for more natural referencing—regardless of name formatting—and helps ensure users can access and navigate mention suggestions without running into glitches.Specific Items Shipped:
-
Support for Spaces in Mentions:
Users can now mention resources whose names include spaces, making it possible to reference a wider range of Collections or assets without workaround or error. -
Revamped Mentions Selector UI:
The selector popup for mentions has been rewritten for a modern, more readable layout, ensuring clearer distinction between assets and Collections and better visual organization. -
Improved Keyboard Navigation:
Keyboard users benefit from improved navigation, with faster cycling through suggestions and more predictable focus management. -
Reliability Fixes for Popup:
The mention suggestion popup no longer gets stuck on the screen, and it closes correctly on outside clicks and Escape key presses (except when focus is in a mention input). -
Popup Positioning and Accessibility:
The popup now displays in a position relative to the text cursor and handles out-of-bounds situations gracefully, improving accessibility and user experience.
Explained Simply:
Think of mentions in Storytell like tagging a friend on social media, but for important files and folders. Before, if you wanted to tag something with a longer name—like “Board Presentations 2024”—the system only recognized the first word, or the popup might freeze, making you start over. Now, you can tag anything, even if the name has spaces. The menu that pops up when you start typing ”@” is easier to read, understands what you mean as you type, and won’t get stuck. Using just your keyboard, you can move through choices and pick the right thing without hassle.Technical Details:
This update completely refactors the mentions extension used in Storytell’s content editor:- The old
@tiptap/extension-mentionimplementation was replaced by a custom ProseMirror node with an integrated autocomplete handler powered by prosemirror-autocomplete, supporting non-canceling space input. - The mention popup is managed through a central state (
useMentionsState), with real-time debounce-driven async search to fetch suggestions from both assets and Collections via a dedicated API. - The popup interface, built as a floating SolidJS Portal component, listens to DOM anchors for accurate positioning using @floating-ui/dom, and provides categorized lists with styled group headers (“Assets”, “Collections”).
- Keyboard and mouse navigation have been unified, and focus/selection state is tracked with explicit interaction type (keyboard vs. mouse) for intuitive response.
- Robust Escape and pointer event handling ensure the popup is dismissed only under appropriate conditions, avoiding legacy “sticky” UI bugs.
- Mentions are rendered as atomic inline nodes, with attributes maintained for both asset and Collection types, and selection dispatches a node replacement in the ProseMirror document.
- This update also adds
prosemirror-autocompleteas a dependency and cleans up legacy extension and matching code.
Storytell can now extract images, tables, and more
Storytell can now extract images, tables, and more
Summary
Storytell now features a significantly improved file content extraction capability, powered by Google’s Gemini 2.0 Flash model. This update enhances how Storytell understands and processes uploaded files, particularly PDFs and images, leading to more accurate and comprehensive data ingestion. You’ll notice higher fidelity markdown generation, better handling of tables and images within documents, and overall improved content quality available for analysis.Key Updates:- Integrated Gemini 2.0 Flash for advanced document and image analysis.
- Improved extraction quality for text, tables, and visual elements within PDFs and images (PNG, JPEG, WEBP).
- Added support for processing Microsoft Word (.docx) and PowerPoint (.pptx) files via conversion.
- Streamlined the ingestion process for faster and more efficient content handling.
Who We Built This For
This feature is designed for anyone who uploads documents or images to Storytell. It’s especially beneficial for users working with complex PDFs containing intricate tables or important visuals, presentations, Word documents, or standalone image files where accurately capturing all content, including text within images or detailed descriptions, is crucial for their analysis and insights within Storytell. (Dan — this one’s for you.)The Problem We Solved With This Feature
Previously, Storytell’s ability to extract content from complex documents and images had limitations. Older methods sometimes struggled to accurately capture text within images, interpret complex table structures, or describe visual elements effectively. This could result in incomplete data or loss of fidelity during ingestion, impacting the quality of search results and analysis. Furthermore, the process involved multiple distinct steps, adding complexity. This new feature addresses these issues by using an advanced vision model to interpret and extract content more holistically and accurately, directly generating high-quality markdown and semantic chunks while streamlining the pipeline.Specific Items Shipped
- New Extractor Service & Interface: We introduced a dedicated
Extractorservice, built on a new Go interface (extract.Extractor), utilizing Google’s Gemini 2.0 Flash model to leverage its multi-modal capabilities for extracting content from various file types. - Advanced PDF & Image Processing: The new service directly processes PDFs, PNGs, JPEGs, and WEBPs using Gemini, extracting text, generating descriptions for visual elements, and converting tables to markdown or HTML based on complexity.
- Document Conversion Support: Added capability to convert Microsoft Word (.docx) and PowerPoint (.pptx) files into PDF using LibreOffice, enabling them to be processed by the new Gemini-based extractor.
- High-Fidelity Markdown & Chunking: Implemented new Go templates (
documents.tmpl,images.tmpl) to guide Gemini in generating well-formatted, comprehensive markdown and semantically relevant content chunks directly from the source files. - PDF Sharding for Large Files: Introduced a
PDFShardercomponent within the extractor service (usingpdftk) that automatically splits large PDFs into smaller, manageable page groups (e.g., 4 pages each) before sending them to the LLM. This overcomes output token limits and ensures complete processing, with state managed idempotently within the ingestion job. - Streamlined Ingestion Pipeline: The ingestion process for supported file types was refactored to use a single
Extractstep, which now handles content extraction, summarization, and chunking previously done by multiple separate steps (like Tika/PDF processing and Summarize). - Infrastructure Updates: Deployed the new
extractorservice to Kubernetes using Helm charts, updated CI/CD workflows for building and deploying the service, and configured necessary GCP permissions and service accounts.
Explained Simply
Imagine you upload a complex report or a presentation with charts and images to Storytell. Before, Storytell might have only pulled out the basic text, maybe getting confused by tables or ignoring the pictures altogether. Now, with our new enhancement, it’s like Storytell has super-vision. It carefully reads the text, understands the layout, describes the images and charts accurately, and even formats tables correctly, presenting all this information neatly. For very long documents, it smartly breaks them into smaller sections to read thoroughly without missing details. This means the information Storytell works with is much more complete and accurate from the start.Technical Details
The core change involves the introduction of thepkg/go/domains/assets/extract package, defining an Extractor interface. The primary implementation, LLMExtractor, leverages the genai Go SDK to interact with the Gemini 2.0 Flash model via its multi-modal API (genai.NewContentFromURI). Extraction logic is guided by Go templates (documents.tmpl, images.tmpl) specific to content types (documents vs. images).A new standalone extractor microservice (Go, Docker, Kubernetes via Helm) was created. This service hosts:PDFSharder: An HTTP endpoint (/v1/pdf-shard) that accepts a signed URL for a PDF, downloads it, usespdftk-java(specifically version3.2.2-1from Debian Bullseye) to split the PDF into chunks (currently 4 pages each), and uploads these shards to a temporary GCS location ($organizationId/tmp/$assetId-$shardNum.pdf).PDFConvertor: An HTTP endpoint (/v1/pdf-convert) that accepts a signed URL for a supported non-PDF file (initially .docx, .pptx), downloads it, useslibreoffice --headless --convert-to pdfto create a PDF version, and uploads the converted PDF to GCS.
pkg/go/domains/assets/ingest/ingester.go) was modified:- A new
Extractstep (process_extract.go) was added for content types supported byLLMExtractor(PDF, PNG, JPEG, WEBP, and convertible types like DOCX, PPTX). - This step first checks if conversion is needed via
conversionRequired. If so, it calls thePDFConvertorendpoint on theextractorservice. - For PDFs (original or converted), it checks if sharding is needed (based on page count/potential token size, though specifics aren’t detailed in the refs) by calling the
PDFSharderendpoint. The shard details (extract.PDFShardedstruct) are stored base64 encoded in the job’s assets (AssetKeyPdfShards). - The
Extractstep iterates through the PDF shards (or processes the single file/shard if not sharded), generating signed URLs for each shard/file and callingp.extractor.Extractwith the appropriateextract.ExtractionRequest(containing the signed URL and content type). - The
processExtractionhelper function handles the call top.extractor.Extract, appends the resulting markdown, generatessearch.Chunkswith sequential IDs, performs embedding, stores embeddings, and updates Collections. It also extracts metadata (display name, summary) from the first shard’s output. - State for processed shards (including chunk count per shard) is updated in the
extract.PDFShardedstruct and saved back to job assets after each shard to ensure idempotency. - Temporary shard files and converted files are cleaned up from GCS upon successful completion.
- The
ErrTokensExceedederror from the extractor is handled specifically, causing a fatal job error. - Previous steps like
PDF(which used Tika) and the separateSummarizestep are bypassed or removed for these file types, as extraction and metadata generation are now handled within theExtractstep.
- New Helm charts (
helm/charts/extractor) for deploying theextractorservice. - Updates to Terraform (
terraform/live/...) to provision the Helm release, configure service accounts (extractor.serviceAccountName), permissions for GCS signed URL generation/access, and secret management. - CI/CD pipeline modifications (
.github/workflows/ci-*.yml,deploy-*.yml) to build theextractorDocker image (usingservices/extractor/Dockerfile) and include it in deployment steps. - Build tooling updates (
Taskfile.yml,magefile.go) for local development and CI builds.
Top Banner for Chrome Extension Promotion
Top Banner for Chrome Extension Promotion
Summary
A new top banner has been added to Storytell website to promote the Chrome Extension, enhancing user engagement and accessibility. The banner includes a prominent call-to-action and a close option for user convenience.Who We Built This For
This feature is designed for all Storytell users, particularly those who would benefit from enhanced browser functionality. It encourages users to install the Chrome Extension, improving their overall experience with Storytell.The Problem We Solved With This Feature
The problem was the lack of a prominent promotion of the Chrome Extension within the Storytell interface. By adding a top banner, we’ve increased the visibility of this tool, making it easier for users to discover and install the extension to enhance their experience.Specific Items Shipped
- Top Banner Component: A new component
LandingPageNavbarBannerhas been created and integrated into the navbar. - Banner Content: The banner includes a call-to-action prompting users to install the Chrome Extension.
- Close Functionality: A close button allows users to dismiss the banner if they prefer not to see it.
- State Management: Signals are used to manage the banner’s visibility, ensuring it behaves responsively across sessions.
Explained Simply
Imagine you’re on a website, and a helpful message appears at the top suggesting a tool that can make your experience better. That’s what this feature does. It adds a banner at the top of Storytell, letting users know they can install a Chrome Extension to get more out of the platform. The banner can be easily closed if the user isn’t interested.Technical Details
- Components: The
LandingPageNavbarcomponent was updated to include the newLandingPageNavbarBanner, which is conditionally rendered based on user interaction. - State Management: SolidJS signals (
createSignal) manage the banner’s visibility state, ensuring it appears only when needed and can be dismissed by the user. - Structure: The banner uses Tailwind CSS for styling, ensuring a responsive and visually appealing design. It includes a call-to-action link and a close button with an icon from
solid-icons/tb. - Integration: The banner is seamlessly integrated into the navbar, maintaining a consistent user interface without disrupting existing functionality.
Auto-Show and Scroll for Hidden Collections
Auto-Show and Scroll for Hidden Collections
Advanced Reasoning Support for AI Models
Advanced Reasoning Support for AI Models
Summary
We’ve improved Storytell’s AI models by adding advanced reasoning support, ensuring more detailed and structured responses. This update also includes UI enhancements, bug fixes, and clarifications on model availability.Who We Built This For:
- Power Users: Professionals needing detailed reasoning in their workflows.
- Developers: Integrating advanced AI capabilities into their applications.
The Problem We Solved:
Storytell’s AI models previously lacked detailed reasoning support, and some models had instruction bugs. This update addresses these issues, providing clearer responses and better functionality.Specific Items Shipped:
-
Enabled Reasoning Support:
Models like DeepSeek R1 now support detailed reasoning, enhancing response quality. -
UI Formatting Updates:
The UI now uses simple text for processing messages, improving readability. -
Bug Fixes:
Resolved issues with models not respecting instructions, ensuring consistent behavior. -
Interstitial Messages:
Added new messages to keep users informed during processing. -
Model Availability Clarification:
The o3 and o4-mini models are not yet released as part of the LLM router, ensuring consistent functionality across available models.
Explained Simply:
Imagine asking a friend for help with a problem. You want them to explain their thought process clearly. This update makes Storytell’s AI explain its thinking step-by-step, just like a helpful friend, making responses more understandable.Technical Details:
- Instruction Handling: Updated to support reasoning instructions, ensuring models provide detailed explanations.
- Model Updates: DeepSeek R1 and other models now correctly handle reasoning tasks with improved temperature settings for better output.
- UI Changes: Removed XML tags for a cleaner interface, enhancing user experience.
- Model Management: o3 and o4-mini models are currently excluded from the LLM router to maintain consistent functionality.
Add OpenAI 4.1 Family to Dynamic LLM Router
Add OpenAI 4.1 Family to Dynamic LLM Router
Summary
Storytell now integrates OpenAI’s latest 4.1 series models, including variants like GPT-4.1, GPT-4.1 Mini, and GPT-4.1 Nano. This update provides access to cutting-edge AI capabilities directly within Storytell. Users can now select from a wider range of models, allowing for greater flexibility in balancing performance, cost, and task suitability. Key updates include:- Integration of new OpenAI 4.1 series models.
- Expanded model selection options within Storytell.
- Access to models with varying performance and cost profiles.
Who We Built This For
This feature is designed for all Storytell users, particularly those who need access to the latest AI advancements for complex analysis or specific tasks. It benefits users seeking more control over the AI models they use, allowing them to choose options that best fit their requirements for capability, speed, or cost-effectiveness.The Problem We Solved With This Feature:
Previously, the selection of AI models within Storytell was limited, preventing users from utilizing the specific advantages of newer models released by OpenAI. This update addresses the need to provide access to state-of-the-art AI, ensuring Storytell remains competitive and powerful. It solves the problem of users being restricted to older models and empowers them to choose the optimal AI for their specific needs within Storytell.Specific Items Shipped:
- OpenAI 4.1 Series Model Integration: Support has been added for new OpenAI models, specifically including the GPT-4.1 series (e.g., GPT-4.1, GPT-4.1 Mini, GPT-4.1 Nano). These models offer different capabilities and efficiencies compared to previously available options.
- Updated Model Selection Interface: The user interface components for selecting AI models within Storytell have been updated to include these new OpenAI 4.1 options, making them readily available for user selection during relevant workflows.
Explained Simply:
Think of Storytell as having different ‘brains’ (AI models) it can use to understand and process information for you. We’ve just added several new, advanced ‘brains’ from OpenAI’s latest 4.1 series. It’s like upgrading your toolbox: maybe you get a super precise screwdriver (like GPT-4.1 Nano) for detailed work, a quick and efficient hammer (like GPT-4.1 Mini) for common tasks, and a powerful sledgehammer (like the main GPT-4.1) for the toughest jobs. Now, within Storytell, you can choose the exact ‘brain’ that’s best suited for what you need to do, giving you more options and better control over results and cost.Technical Details:
The integration involved updating Storytell’s backend services to communicate with the OpenAI API endpoints corresponding to the new 4.1 series models (e.g., GPT-4.1, GPT-4.1 Mini, GPT-4.1 Nano). This included adapting API call structures, handling authentication, and ensuring proper request/response processing for these specific models. These new model identifiers have been registered within Storytell’s internal model management system. Configuration changes were deployed to make these models selectable through the application’s standard model selection mechanisms, both via API and the user interface. Infrastructure adjustments may have been made to accommodate the potential resource requirements or interaction patterns of these newer models.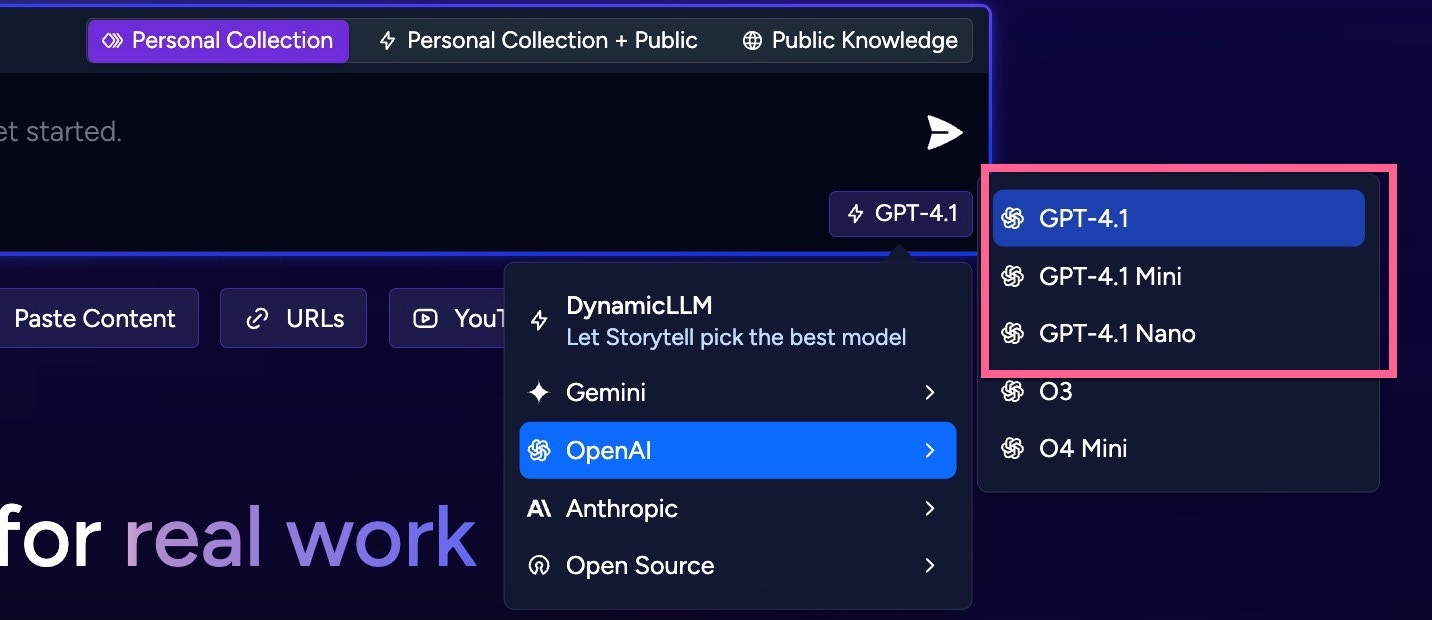
Automatic Prompt Improvement
Automatic Prompt Improvement
Summary
We’ve launched a new Automatic Prompt Improvement feature that helps you create more effective prompts without requiring expert knowledge. As you type your prompts, Storytell now intelligently analyzes your text and suggests enhanced versions that are more likely to produce better results. The system works in the background, watching for pauses in your typing before offering improvements. You can instantly apply these suggestions with a single click or explore additional enhancement options.Who We Built This For
This feature was built for all Storytell users who want to create more effective prompts but may not have expertise in prompt engineering. It’s especially valuable for:- Content creators seeking to get the best possible outputs
- New users who are still learning effective prompt construction techniques
- Professionals who need optimal results but want to save time on prompt refinement
- Anyone who wants to improve their prompt writing skills by learning from AI-generated suggestions
The Problem We Solved With This Feature:
Writing effective prompts for AI systems requires skill and experience. Many users struggle to articulate their requests in ways that yield optimal results, leading to frustration and wasted time on multiple attempts. Previously, users had to manually refine their prompts through trial and error or study prompt engineering techniques. This feature solves this problem by automatically analyzing user prompts and suggesting improvements in real-time, helping users get better results on their first try while simultaneously teaching them better prompt writing techniques through example.Specific Items Shipped:
- Real-time Prompt Enhancement - The system actively analyzes your prompt as you type, waiting for natural pauses to suggest improvements. Once you’ve written at least 3 words and paused typing for 1.5 seconds, the system begins generating a better version of your prompt based on prompt engineering best practices.
- One-Click Application - When an improved prompt suggestion is ready, you can apply it with a single click, instantly replacing your original text with the enhanced version. This makes the process of improvement completely frictionless.
- Advanced Options - For users who want more control, we’ve included a “More options” button that opens a modal with additional enhancement capabilities and customization controls.
- Seamless Visual Integration - The UI for this feature smoothly integrates into the existing prompt interface, showing status indicators like “Improving your prompt” during processing and clear call-to-action buttons when suggestions are ready.
-
Intelligent Context Preservation - The system ensures that special syntax and references (like
@[id]"Name") are preserved exactly as they were input, maintaining compatibility with other Storytell features.
Explained Simply:
Imagine you’re trying to write an email to someone important, but you’re not sure if your wording is clear or persuasive enough. Normally, you might ask a friend to look over it and suggest improvements before you send it. That’s what this new feature does, but for your AI prompts.As you’re typing your request to Storytell, the system watches what you’re writing. When you pause for a moment (like when you’re thinking about what to say next), it quickly analyzes your text and comes up with a better version based on what works well for getting good results from AI systems.Then it shows you this improved version and gives you a simple button to use it if you want to. The improved prompt might include clearer instructions, better organization, or more specific details that help the AI understand exactly what you’re looking for. It’s like having a prompt-writing expert looking over your shoulder and offering suggestions, but it happens automatically and instantly.Technical Details:
The Automatic Prompt Improvement feature is implemented through a combination of frontend debouncing techniques and backend prompt enhancement services:-
On the frontend, we’ve added a new
PromptAutoImprove.tsxcomponent that monitors the editor state through TipTap’s update events. The system employs a 1.5-second debounce mechanism to detect when users have paused typing, at which point it triggers the enhancement process for prompts containing at least 3 words. -
The enhancement request is sent to the
/controlplane.PromptEnhancerendpoint with a type parameter of"auto_improve". This endpoint processes the raw prompt through specialized instruction templates defined in Go embed files (templates/auto_improve_prompt.md). These templates guide the backend LLM to analyze the prompt against core enhancement principles including context enrichment, structural optimization, clarity and precision, role perspective definition, and brevity. -
The server response includes a JSON object with a
prompt_enhanced.contentarray containing the suggested improvement. Upon receiving this response, the UI transitions from the “Improving your prompt” state to displaying the suggestion with action buttons. - The implementation includes careful state management to handle scenarios such as continued typing during enhancement (which cancels previous attempts), tracking of already-improved prompts to prevent recursive enhancement, and preservation of special syntax patterns like `@[id]“Name
Prompt Library
Prompt Library
Summary
Storytell now offers a powerful new Prompt Library feature that enables users to save, organize, and reuse prompts across conversations. Users can now store frequently used prompts in their personal library or share them across team Collections, making knowledge work more efficient and consistent. The Prompt Library is accessible directly from the chat interface, allowing you to quickly insert saved prompts into new conversations or save effective prompts for future use.Who We Built This For
We built the Prompt Library for knowledge workers who frequently use similar prompts in their workflow, including content creators, researchers, analysts, and teams who want to standardize their approach to querying information. This feature is especially valuable for collaborative teams who want to share effective prompts across departments and for individuals who want to maintain a personal Collection of proven conversation starters.The Problem We Solved With This Feature
Before the Prompt Library, users had to manually rewrite or copy-paste prompts they used frequently, leading to inconsistency, wasted time, and lost knowledge. Advanced users would create their own external libraries of effective prompts, but these were disconnected from Storytell itself. Organizations had no systematic way to capture and share institutional knowledge about effective ways to query their data. The Prompt Library solves these problems by providing a built-in system for prompt management that’s integrated with Storytell’s permissions model and collaboration features.Specific Items Shipped
- Personal Prompt Library - Users can now save prompts to their personal library for quick access. Each saved prompt includes a title, description, and the prompt text itself, making it easy to organize and find the right prompt when needed.
- Shared Collection Prompts - Teams can build a shared repository of effective prompts through Collections. When a prompt is saved to a shared Collection, anyone with access to that Collection can view and use the prompt, facilitating knowledge sharing across teams.
- Prompt Library Drawer - A dedicated interface allows users to browse, search, and manage saved prompts. The drawer can be accessed from the chat interface and displays prompts according to the user’s permissions and selected Collections.
- Save to Library Modal - When users discover an effective prompt, they can save it to their library with just a few clicks. The modal allows selecting where to save the prompt (personal or shared Collection) and adding metadata to make it findable later.
- Prompt Reuse - Saved prompts can be inserted directly into the chat interface, allowing quick reuse without retyping. This ensures consistency in how questions are framed and makes it easy to use proven prompts repeatedly.
Explained Simply
Imagine you’re a student who keeps a notebook of really good questions that help you understand different subjects. Each time you come up with a great question that gets you a helpful answer, you write it down so you can use it again later.The Prompt Library works like that notebook, but it’s built right into Storytell. When you create a prompt that works really well, you can save it with a title and description. Later, when you’re working on something similar, you can open your library and grab that question instead of trying to remember exactly how you worded it before.The really cool part is that you can choose to put some prompts in your personal library (like your private notebook) or in a shared Collection (like the class notebook everyone can use). This way, when someone on your team discovers a really effective way to ask something, everyone can benefit from that knowledge.Technical Details
The Prompt Library implementation spans multiple layers of the Storytell architecture:Backend:- New StoredPrompt domain type was created with full event sourcing support
- Database tables ss_stored_prompts (snapshots) and es_stored_prompts (events) were added to store prompt data and history
- CRUD operations were implemented with Collection-based authorization checks, ensuring users can only access prompts they have permission to view
- Migration scripts were added for schema changes and validator registration
- New endpoints were created:
- CreateStoredPrompt - Creates prompts in specified Collections with authorization checks
- UpdateStoredPrompt - Modifies existing prompts including Collection migration
- DeleteStoredPrompt - Soft deletes prompts (maintaining history)
- ListStoredPrompts - Provides paginated retrieval with filtering
- Collection sharing functionality was enhanced with proper authorization checks for prompts
- PromptLibraryDrawer component was implemented for browsing and managing prompts
- SaveToPromptLibraryModal component was created for saving new prompts or editing existing ones
- Collection picker was added for organizing prompts across personal and shared libraries
- Integration with the chat interface allows seamless saving and reuse of prompts
- The prompt editor uses TipTap with customized extensions for a richer editing experience
LLaMA 4 Scout Now Available for Manual Selection
LLaMA 4 Scout Now Available for Manual Selection
Summary
We’ve added Meta’s LLaMA 4 Scout model to Storytell, giving you access to a powerful new language model option. This 17B parameter model offers exceptional capabilities in quantitative reasoning and coding tasks, with a massive 102,400 token context window. LLaMA 4 Scout is now available for manual selection, allowing you to experiment with its capabilities for your specific use cases.Who We Built This For
This feature is built for users who need advanced reasoning and coding capabilities, specifically:- Data analysts working with complex numerical problems
- Developers needing assistance with code generation
- Researchers processing large documents who need extended context windows
- Users seeking a cost-effective alternative to larger models
The Problem We Solved With This Feature
By adding LLaMA 4 Scout, we’re addressing the need for more model options with different capability profiles. Not all tasks require the largest, most expensive models, and some specific use cases benefit from models with particular strengths. LLaMA 4 Scout excels at quantitative reasoning and coding while being more cost-effective than larger models, giving users more flexibility to choose the right tool for specific tasks.Specific Items Shipped
- New LLaMA 4 Scout model integration - We’ve integrated Meta’s 17B parameter LLaMA 4 Scout model, featuring a 102,400 token context window and 8,192 token maximum output. This model is now available for manual selection when creating prompts.
- Competitive token pricing - LLaMA 4 Scout is available at 0.34 per 1,000 completion tokens, making it a cost-effective option for many use cases.
- Specialized capabilities profile - The model exhibits particular strengths in quantitative reasoning (0.844) and coding (0.826), with moderate reasoning knowledge (0.582) and scientific reasoning (0.336) capabilities.
Explained Simply
Think of Storytell as a workshop with different types of tools. We just added a new tool to your workshop - LLaMA 4 Scout. It’s like a specialized calculator that’s really good at math problems and helping write computer code, but it can also handle other tasks reasonably well.What makes this tool special is that it can “remember” a lot more information at once than many other tools (about 102,400 words worth!), and it costs less to use than some of the bigger, more expensive tools. It’s like getting a tool that’s really good at specific jobs without paying for the premium all-purpose tool when you don’t need it.For now, you’ll need to specifically choose this tool when you want to use it, rather than having Storytell automatically suggest it. This gives you the chance to try it out and see if it works well for your specific needs.Technical Details
LLaMA 4 Scout (meta-llama/llama-4-scout-17b-16e-instruct) is a 17B parameter model from Meta’s LLaMA 4 family. The implementation includes:- Model specification with a context window of 102,400 tokens and maximum output of 8,192 tokens
- Token pricing set at 0.34 for completion tokens
- Performance metric of 109,419.00 with a cost rating of 0.263
- Capability rankings across multiple categories (Quantitative Reasoning: 0.844, Reasoning Knowledge: 0.582, Coding: 0.826, Scientific Reasoning: 0.336)
- Streaming support enabled with a maximum response time of 1 minute
- Manual selection only (not added to the LLM router)
To consider
- Consider creating specific example prompts that showcase LLaMA 4 Scout’s strengths in quantitative reasoning and coding to help users understand when to select this model.
- Explore setting up comparison documentation between LLaMA 4 Scout and other models on the platform to help users make informed decisions about which model to use for specific tasks.
- Consider implementing a feedback mechanism specifically for LLaMA 4 Scout usage to gather data about performance and user experience, which could inform decisions about adding it to the automatic router in the future.
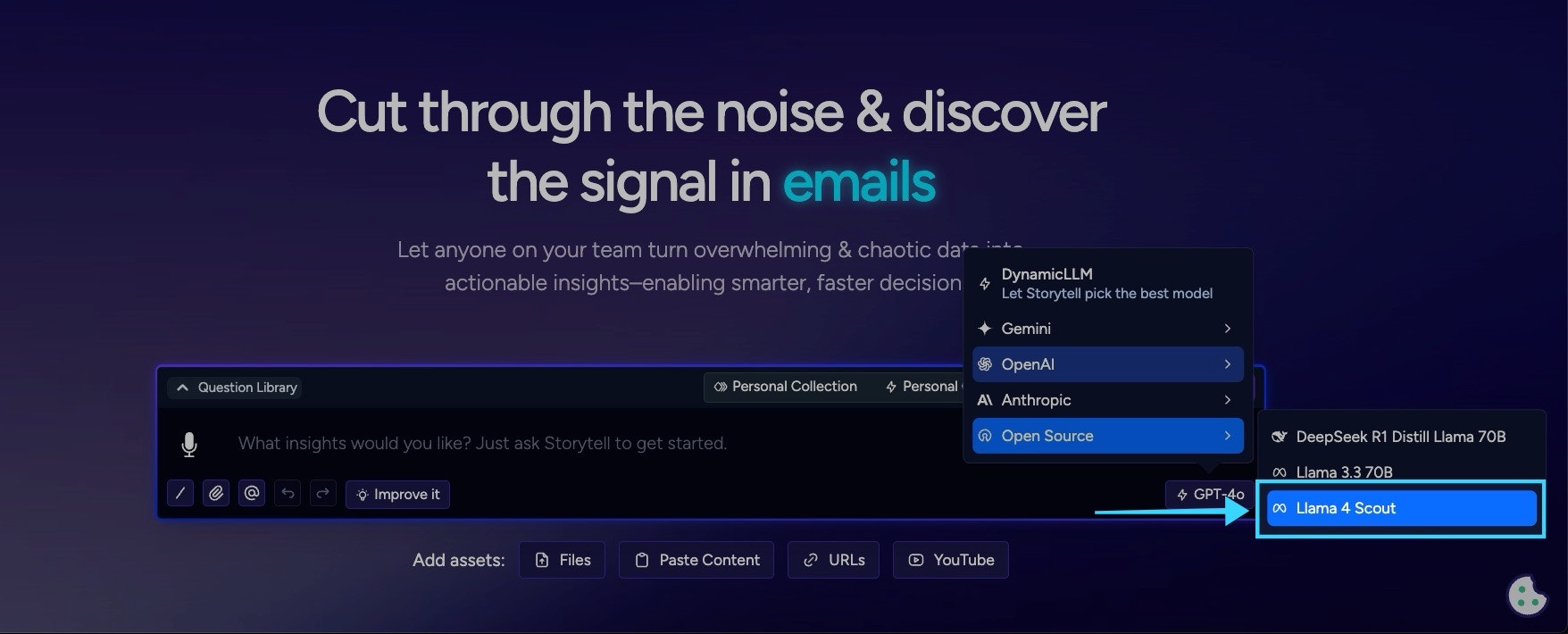
Enhanced Error Streaming for Improved Client Interaction
Enhanced Error Streaming for Improved Client Interaction
Summary
This recent update to Storytell significantly refines error handling by streaming error messages to clients during prompt processing. The objective is to reduce the jarring “fatal” error experience by integrating these errors into the normal response flow.- Visible Error Communication: Enhances user awareness of errors occurring during prompt processing.
- Improved System Transparency: Shifts error handling to provide real-time updates rather than ending abruptly with fatal errors.
- Updated Compatibility: The system now runs with
expectedEncoreVersionv1.46.16.
Who We Built This For
This enhancement is targeted at users actively using Storytell for prompt executions, including developers and data operators who benefit from continuous feedback and seamless operations.The Problem We Solved With This Feature
Previously, users encountering errors during prompt processing faced an abrupt stop signaled by fatal error messages. This led to confusion and disrupted workflows. By streaming these errors instead, users now receive real-time updates, maintaining workflow continuity and providing better insight into potential issues.Specific Items Shipped:
- Error Streaming Implementation: Redesign in
PromptBuilderV2.Process()enables errors to be streamed instead of causing abrupt failures. - Introduction of ErrStreamedToClient: New error handling layers to ensure specific streaming errors are recognized.
- Dependency Update: From v1.46.14 to v1.46.16, ensuring system compatibility and stability in error handling.
Explained Simply:
Imagine your car giving you updates about engine problems while you’re driving, instead of suddenly breaking down without notice. This update ensures that if something goes wrong during the prompt processing, users are informed step-by-step, enabling better handling instead of an unexpected stop.Technical Details:
New Features:
- Streamed errors are incorporated into the standard communication flow with users, utilizing the
ErrStreamedToClienterror type in processes withinPromptBuilderV2andMessagePromptV2. - Changes in error handling ensure that once a problem is identified, it’s signalled back to users, preventing the abrupt cessation previously experienced.
Bug Fixes:
- Compatibility enhanced with an elevated
expectedEncoreVersion, addressing errors seamlessly across updated platform versions. - Adaptations in message handling codes ensure warnings are efficiently transmitted without interrupting user activity.
Content Upload Experience with the Prompt Bar
Content Upload Experience with the Prompt Bar
Summary
We’ve streamlined how you add content to Storytell with a unified upload experience. Now, all file uploads, pasted content, URLs, and YouTube links are accessible directly from the prompt bar, making it easier than ever to enrich your SmartChats™ and Collections. This change originated from wanting users to “always go to the same place to upload content”Key updates:- Centralized content upload options
- Improved accessibility across all views
Who We Built This For
This update benefits all Storytell users, particularly those who frequently add files, links, or other content to their SmartChats™ and Collections. It simplifies the content addition process, saving time and effort.The Problem We Solved With This Feature
Previously, content upload options were scattered across different views within Storytell. This inconsistency made it difficult for users to quickly and easily add content to their SmartChats™ and Collections. By centralizing these options in the prompt bar, we’ve created a more intuitive and efficient workflow.Specific Items Shipped
- Moved File Upload to Prompt Bar: The file upload functionality is now located in the prompt bar, accessible from any view within Storytell. This ensures users always know where to go to upload content, regardless of the current screen or task.
- Added Asset Buttons: New buttons for adding files, pasting content, URLs, and YouTube links have been added to the prompt bar. These buttons provide quick access to the various content upload options, streamlining the process of adding assets to SmartChats™ and Collections.
Explained Simply
Imagine you’re trying to share a cool video or document with your friends. Before, you had to go to different places to attach a file, paste a link, or find a YouTube video. Now, it’s like having one central “Add Content” button that lets you do all those things from the same spot. It makes sharing stuff way easier and faster.Technical Details
- ENG-2893: The file upload functionality was moved to the prompt bar by modifying the FloatingPromptBarContainer.tsx and PersistentPrompt.tsx files. The setShowUploadModal function in PromptContext.tsx was updated to handle different upload types (“files”, “paste”, “web”, “youtube”).
Why Storytell Link Added to Navigation Bar
Why Storytell Link Added to Navigation Bar
Summary
Storytell now features a direct link to the “Why Storytell” page in the navigation bar. This makes it easier for users to quickly access information about the value proposition of Storytell and how it can benefit their organization. This update ensures that potential users can efficiently find key information to understand Storytell’s unique benefits.Who We Built This For
This update is primarily beneficial for potential enterprise clients and users who are evaluating Storytell. It helps them understand the platform’s capabilities and value proposition more easily.The Problem We Solved With This Feature
Previously, users had to navigate through multiple pages or rely on external search to find information about “Why Storytell.” This created friction and potentially hindered the evaluation process. Adding a direct link improves discoverability and simplifies access to this essential information.Specific Items Shipped
- “Why Storytell” Link in Navbar: A new link labeled “Why Storytell” has been added to the main navigation bar, both on desktop and mobile views. This link directs users to the dedicated “Why Storytell Enterprise AI” page, highlighting the benefits and use cases of Storytell.
Explained Simply
Imagine you’re shopping online for a new gadget, and you want to know why you should buy this one instead of the others. Usually, you’d have to hunt around the website for the “Why This Gadget?” section. With Storytell, we’ve put a “Why Storytell?” button right at the top, so anyone can easily see what makes Storytell special without having to search around.Technical Details
The change involves modifying theLandingPageNavbar.tsx file within the pkg/ts/core/src/marketing/components directory. Specifically, a new <li> element containing an <a> tag was added to both the NavbarMobile and LandingPageNavbar components. This <a> tag points to https://web.storytell.ai/why-storytell-enterprise-ai and includes the text “Why Storytell” with appropriate styling. The commit was verified with GitHub’s verified signature, using GPG key ID B5690EEEBB952194.
Expanded Language Support - Chinese Simplified and Traditional
Expanded Language Support - Chinese Simplified and Traditional
Summary
Storytell now supports Chinese Simplified (zh_CN) and Chinese Traditional (zh_TW) languages. This update broadens Storytell’s accessibility, allowing a larger global audience to engage with the platform in their native language. This feature adds the Chinese language to the Storytell platform, enabling users in China to utilize the platform effectively.Who We Built This For
This update is specifically designed for Chinese-speaking users, enabling them to interact with Storytell in their preferred language. The feature benefits users who prefer to use Storytell in Chinese for improved comprehension and engagement. Colin from GMI may be one such user.The Problem We Solved With This Feature
The addition of Chinese language support addresses the need for inclusivity and accessibility. Many users find it easier and more efficient to interact with digital platforms in their native language. By offering Chinese Simplified and Traditional, Storytell eliminates language barriers and improves the overall user experience for a significant portion of the global population.Specific Items Shipped
- Chinese Simplified Language Support: Storytell now supports Chinese Simplified (zh_CN) as a language option. This includes translation of the user interface, prompts, and other relevant content.
- Chinese Traditional Language Support: In addition to Simplified Chinese, Storytell also offers support for Chinese Traditional (zh_TW). This ensures that users who prefer the Traditional script can effectively use the platform.
Technical Details
The update includes the addition of Chinese Simplified and Traditional to the supported languages within thepkg/ts/core/src/lib/data/lanugagesByPopularity.ts file. This involves adding the appropriate language codes (“zh_CN”, “zh_TW”) and names (“Chinese - Simplified”, “Chinese - Traditional”) to the language configuration.Explained Simply
Imagine Storytell is like a store that only speaks English. Now, we’ve added translators who can speak Chinese, both Simplified and Traditional. This means that more people can now easily use Storytell, no matter which version of Chinese they prefer. It’s like making sure everyone feels welcome and can understand what’s going on.Link Sharing for Collections
Link Sharing for Collections
Summary
The Link Sharing for Collections feature allows users to share Collections with others via a unique, generated link. Anyone with the link can join the Collection, even if they don’t have an existing account. Upon clicking the link, users are prompted to register or sign in. Once authenticated, they gain access to the shared Collection. This simplifies the process of inviting new users to collaborate on Collections.Who we built this for
This feature is designed for:- Existing Storytell users: To easily share Collections with external collaborators or new users without needing to manually invite each person.
- New Storytell users: To seamlessly join shared Collections through a simple registration process, encouraging platform adoption and collaboration.
The problem we solved with this feature
Previously, inviting new users to a Collection required manually adding them, which could be cumbersome and time-consuming, especially for large groups or external collaborators. This feature streamlines the onboarding process by enabling Collection owners to simply share a link, making it easier to grow their community and collaborate effectively. This reduces friction for new users and simplifies sharing Collections for existing users.Specific items shipped:
- Secret Link Generation:
- Summary: A unique, secure link is generated when sharing a Collection.
- Detail: When a user shares a Collection and chooses the “secret link” option, the system generates a unique token (a
share_public_tokenwhich is achar(68)) and stores it in thecontrolplane.dat_collection_link_sharestable. This token is then used to construct a shareable URL.
- Access Control and Permissions:
- Summary: The feature ensures that only users with the link and valid permissions can access the Collection.
- Detail: The
controlplane.create_collection_secret_sharefunction checks if the acting user has the required permission on the Collection before creating the share record. Access is granted through theAcceptCollectionSecretLinkTokenfunction incurator_core_accept_collection_secret_link_token.goafter validating the token and creating appropriate Collection grants.
- Database Migrations:
- Summary: Database schema was updated to support the new secret link sharing feature.
- Detail: The
services/controlplane/migrations/50_collection_secret_link_sharing.up.sqlmigration creates thecontrolplane.dat_collection_link_sharestable to store the secret link details. It also creates the functioncontrolplane.create_collection_secret_shareto create the new Collection share record
- API Endpoints:
- Summary: New API endpoints were created to accept and delete Collection secret links.
- Detail: The
AcceptCollectionsSecretLinkendpoint (endpoint_collection_secret_link_accept.go) allows users to join a Collection using a secret link. TheDeleteCollectionsSecretLinkendpoint (endpoint_collection_secret_link_delete.go) allows Collection owners to revoke a secret link, invalidating it for future use.
- User Redirection and Registration:
- Summary: New users are redirected to register or sign in before gaining access.
- Detail: When a user clicks on a secret link, the system checks if they are authenticated. If not, they are redirected to the registration or sign-in page. After successful authentication, they are granted access to the Collection.
- Access Redaction
- Summary: When a secret link is used, email addresses are redacted
- Detail: The
GetCollectionAccessfunction incurator_core_get_collection_access.goredacts the email address to only show the domain.
Explain it to me like I’m five
Imagine you have a clubhouse (a Collection). Instead of inviting each friend one by one, you can now create a special “secret link” that acts like a magic ticket. You give this link to anyone you want to join your clubhouse. When they click the link, they can sign up (if they’re new) or sign in (if they already have an account), and BAM! They’re automatically members of your clubhouse. It’s like a super-easy way to invite lots of friends without having to do it individually.Technical details
The implementation involves several key components:- Database Schema: The
controlplane.dat_collection_link_sharestable stores information about the shared link, including the token, Collection ID, sharing user, and permissions. - API Endpoints:
AcceptCollectionsSecretLink(POST /v1/collection-secret-token/:publicToken): This endpoint handles the acceptance of a secret link token. It verifies the token, retrieves the associated Collection share record, and grants the user access to the Collection.DeleteCollectionsSecretLink(DELETE /v1/collection-secret-token/:tokenID): This endpoint revokes a secret link by deleting the corresponding record from thecontrolplane.dat_collection_link_sharestable.
- Curator Core Functions:
AcceptCollectionSecretLinkToken(curator_core_accept_collection_secret_link_token.go): This function validates the secret link token, retrieves the Collection share record, builds collection grants, and grants access to the user.DeleteCollectionSecretLinkToken(curator_core_delete_collection_secret_link_token.go): This function deletes a secret link token and its associated grants.GetCollectionAccess(curator_core_get_collection_access.go): This function checks if the current session user has access to the Collection via a secret link and redacts the email.
- Security: The
VerifyShareTokenfunction is used to ensure that the token is well-formed before performing any expensive operations. - Integration Tests: The
services/controlplane/test/integration/collection_share_test.gofile contains integration tests that verify the functionality of the secret link sharing feature, including creating, accepting, and deleting secret links.
Map-Reduce Architecture for Large Language Models
Map-Reduce Architecture for Large Language Models
Summary
Storytell now supports Map-Reduce functionality for Large Language Models, enabling more effective processing of lengthy content and complex queries. This architectural improvement provides better handling of large datasets by breaking them into manageable chunks, processing them independently, and then combining results. Users will experience improved responses when working with extensive documents or complex queries that require analyzing multiple references.Who We Built This For
This feature was built for users who work with large knowledge bases, extensive documentation sets, or need to analyze multiple documents simultaneously. It’s particularly valuable for research teams, content strategists, and knowledge workers who require comprehensive analysis across multiple information sources.The Problem We Solved With This Feature:
Previously, when dealing with large volumes of information, LLMs would either hit context limitations or provide incomplete answers that failed to incorporate all relevant information. This led to inconsistent results when processing extensive documentation or when answers required synthesizing information from multiple sources. Map-Reduce solves this by enabling systematic processing of large information sets while maintaining coherent, comprehensive responses.Specific Items Shipped:
-
Map-Reduce Architecture:
Implemented a distributed processing approach that breaks large datasets into manageable chunks, processes each independently, and then combines the results into a coherent response. -
Enhanced Debugging Capabilities:
Added comprehensive debugging tools that provide visibility into the execution process, making it easier to troubleshoot and optimize performance. -
Improved Resource Management:
Implemented structured accounting for token usage based on actual LLM reports rather than internal estimates, providing more accurate usage metrics. -
Standardized LLM Integration:
Refactored how prompt building and execution occurs, creating a consistent interface for all LLM interactions regardless of where execution happens.
Explained Simply:
Imagine you’re researching a complex topic for a school project that requires reading 20 books. Without help, you’d need to read all the books cover-to-cover, remember everything, and then write your report. That’s exhausting and you’d probably miss important details.Map-Reduce is like having a study group where each person reads a different book, takes notes on the important parts, and then everyone comes together to combine their findings into one comprehensive report. This way, all the important information gets included, and the final report is more complete than if any one person tried to read everything.Storytell now works similarly when processing large amounts of information. It breaks up big tasks into smaller pieces, handles each piece separately, and then combines the results into one coherent answer - giving you better, more comprehensive responses when working with lots of information.Technical Details:
The Map-Reduce implementation consists of several key components:The system introduces a core ai.Streamer interface in pkg/go/domains/ai with specific implementations for each LLM vendor (e.g., OpenAI, Gemini).The execution flow:- Input content is divided into chunks that fit within model context windows
- A “mapper” prompt processes each chunk independently
- A “reducer” prompt combines and synthesizes the outputs from all mappers
- The final reduced output is returned as a cohesive response
- A new debugging framework in pkg/go/domains/debug provides structured capture of execution details, including token usage, response fragments, and timing metrics. Debug output is stored in a standardized JSON format at
{{bucket}}/{{organization}}/debugged/prompt/{{messageId}}.json.
Gemini 2.0 Pro Model
Gemini 2.0 Pro Model
Summary
Storytell now integrates Gemini 2.0 Pro, replacing Gemini 1.5 Pro. This upgrade brings Google’s latest large language model capabilities to Storytell, offering improved reasoning, understanding, and response quality. As part of this update, we’ve also streamlined our model offerings by removing several less effective models to optimize the experience.Who We Built This For
This feature was built for all Storytell users who rely on high-quality AI assistance. It’s particularly valuable for users working on complex tasks that require sophisticated reasoning, document analysis, or nuanced responses.The Problem We Solved With This Feature:
Google announced that Gemini 1.5 models will be deprecated in the coming months, which would have eventually caused disruptions for users. Additionally, there was an opportunity to improve overall response quality by upgrading to Google’s latest model. This update ensures continued support while providing access to Google’s most advanced AI capabilities.Specific Items Shipped:
- Gemini 2.0 Pro Model: Integrated Google’s latest Gemini 2.0 Pro model, offering improved reasoning capabilities and response quality compared to the previous 1.5 version.
- Model Cleanup: Removed several underperforming models (AnthropicClaude3Haiku, GoogleGemini15Flash, and MetaLlama323bPreview) to streamline options and focus on the highest-performing models.
- Ranking Updates: Removed the Artificial Analysis ranking system which was discontinued by the provider, ensuring that model selection remains based on current, relevant metrics.
Explained Simply:
Think of large language models like different chess engines that help you play better chess. We’ve just upgraded from a good chess engine (Gemini 1.5 Pro) to an even better one (Gemini 2.0 Pro) that sees more moves ahead and makes smarter decisions.At the same time, we removed some older chess engines that weren’t as helpfulRetry Button for Failed File Uploads
Retry Button for Failed File Uploads
YouTube Scraping Integration
YouTube Scraping Integration
Summary
This feature redefines how Storytell extracts and processes YouTube content. By shifting to a ScrapingBee-based solution, we now reliably retrieve video page HTML and transcripts. The integration leverages premium proxy settings and advanced header forwarding techniques to improve rendering and data accuracy.Who we built this for
- Content Curators & Data Analysts:
Users who need accurate metadata and transcript data from YouTube videos to populate content repositories, enhance search functionality, and power data-driven insights. - Developers:
Teams that rely on seamless integrations to fetch, process, and analyze video content without dealing with unstable scraping techniques.
The problem we solved with this feature
We encountered challenges with the legacy method of extracting YouTube content using Firecrawl, which often resulted in incomplete transcript data and unreliable HTML scraping. This issue directly affected users who depend on accurate video metadata for content analysis and discovery. By introducing the ScrapingBee-based approach, we solved these reliability and performance issues, ensuring that our clients can confidently ingest and use YouTube video data.Specific items shipped
-
YouTube Transcript Extraction Overhaul:
We restructured the function incrawl_strategy_youtube.goto utilize ScrapingBee for retrieving video page content. This not only provides a more reliable method to fetch transcripts but also ensures a robust fallback in case captions are missing. The enhanced workflow minimizes errors and improves data completeness. -
ScrapingBee Integration Module:
A new module, encapsulated inpkg/go/domains/assets/ingest/web/scrapingBee.go, was introduced. This module handles HTTP requests to the ScrapingBee API, forwarding necessary headers and managing proxy configurations. It abstracts the complexity of the scraping process to provide a simple interface for content extraction. -
Configuration and Dependency Updates:
With the transition from Firecrawl to ScrapingBee, relevant dependencies have been updated ingo.modand unused dependencies removed fromgo.sum. Configuration files now require a ScrapingBee API key, ensuring that the setup is streamlined for the new integration. -
Codebase Streamlining:
Legacy scraping functionality was removed and replaced with concise, maintainable code. This cleanup not only reduces technical debt but also makes future updates to our scraping strategies easier to implement.
Explain it to me like I’m five
Imagine you have a magic net that catches butterflies (YouTube videos) and shows you pretty pictures (video webpages) and tells you the stories they share (transcripts). Our old net sometimes missed parts of the stories. We built a better net that catches more details, so everyone can enjoy the full story every time!Technical details
At its core, the new feature uses the ScrapingBee API to perform HTTP GET requests. It constructs requests by encoding the target YouTube URL and sets parameters such asRenderJS and PremiumProxy to ensure complete rendering of dynamic content. The integration allows header forwarding, meaning custom HTTP headers can be added to mimic browser behavior—essential for bypassing common scraping pitfalls. After receiving the response, the module processes the HTML to extract essential metadata like the title and description. Additionally, the transcript extraction logic uses XML parsing to decode caption data. This shift not only replaces the older Firecrawl implementation (which has now been fully removed) but also makes the system more robust by combining effective error handling, improved dependency management, and a simplified code architecture.Next Steps & Considerations:
- Investigate further API performance metrics to benchmark the reliability of ScrapingBee over the previous Firecrawl method.
- Develop comprehensive documentation and unit tests for the new scraping module to ensure future maintainability.
- Explore potential error logging improvements and configuration diagnostics to quickly detect changes in YouTube’s page structure that might affect transcript extraction.
New way to override LLM Router aka the 'Jeremy' feature
New way to override LLM Router aka the 'Jeremy' feature
Summary
Storytell now gives you direct control over which AI model processes your prompts with our new LLM Selection feature. Users can now override the default dynamic model selection and specifically choose models like O3 Mini, GPT-4o, Claude, or Gemini for their particular needs. This feature puts more power in your hands to optimize your AI interactions for specific types of queries. The UI offers an intuitive dropdown menu that makes selecting your preferred AI model simple and straightforward.Who We Built This For
We built this feature specifically for users like Jeremy who need greater control over which AI models handle their prompts. This feature serves professionals who work with specialized content where certain AI models perform better than others for specific tasks.The Problem We Solved With This Feature:
Previously, Storytell would automatically select the best AI model for each prompt using our dynamic LLM routing system. While this works well in most cases, power users sometimes need to specify a particular model because they know it performs better for certain types of queries or content. Without manual selection capability, users couldn’t leverage their knowledge of model strengths or preferences, limiting the control they had over their AI interactions.Specific Items Shipped:
- LLM Selection Dropdown - Added an intuitive dropdown menu in the chat interface that allows users to select specific AI models instead of relying on automatic model selection. The dropdown includes options for various models from different providers including OpenAI, Anthropic, Google, and open-source options.
- Model Categorization - Organized available models by vendor (OpenAI, Anthropic, Google, etc.) to make finding specific models more intuitive. This structure helps users quickly navigate to their preferred model family.
- Default “Dynamic LLM” Option - Maintained the original automatic model selection as the default option, ensuring that casual users still benefit from Storytell’s intelligent routing while giving power users the ability to override when needed.
- Visual Indicators for Selected Models - Implemented visual feedback that clearly shows which model is currently selected, making the system state obvious to users at all times.
Explained Simply:
Imagine you have a toolbox with different types of screwdrivers. Before this update, Storytell would automatically pick what it thought was the best screwdriver for each job. That works great most of the time, but sometimes you know exactly which screwdriver you need because you’ve done similar work before.Now, with this new feature, you can reach into the toolbox and grab exactly the screwdriver you want. Some screwdrivers (AI models) are better at creative writing, others at analyzing data, and some at producing concise answers. If you’re working on a project where you know a specific AI model works best, you can now select it directly instead of letting Storytell choose for you.It’s like being able to pick between different expert assistants based on what you know about their strengths and how they match your specific needs at that moment.Technical Details:
The LLM Selection feature introduces a new UI component in the chat interface that integrates with the existing prompt context system. The implementation uses a dropdown menu created with the StDropdown component, which renders available model options organized by vendor.The feature maintains a model selection state that’s initialized as undefined (which triggers the default dynamic model selection). When a user selects a specific model, the state updates to store the exact model ID (e.g., “o3-mini”, “gpt-4o”, “claude-3-7-sonnet-latest”).The backend already supported model specification in requests, accepting both vendor names (like “openai” or “anthropic”) and specific model IDs. The frontend implementation now passes these specific model IDs when selected by the user.The UI builds the dropdown hierarchically, with main categories for:- Dynamic LLM (default)
- OpenAI models (GPT-4o, O1, O1 Mini, O3 Mini)
- Anthropic models (Claude variants)
- Google models (Gemini variants)
- Open Source models (DeepSeek, Llama)
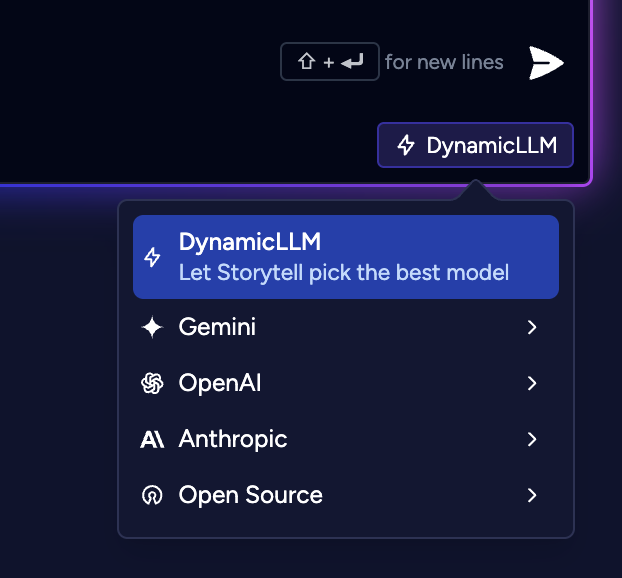
Chat Thread Attachments
Chat Thread Attachments
Summary
This feature enables each chat thread to carry one or more attachments. In practice, a user can now include extra files or pieces of text (such as bits of content extracted from web pages) with any text prompt. The attachments are stored only as part of the thread’s local state and are not indexed for search or embedded into the knowledge base. This design supports use cases where a user wants to have a one‑off conversation or “chat session” enriched with extra details or references without cluttering the overall knowledge base.Who We Built This For
- Chrome Extension Users and Chat-focused Customers
We built this feature for users who interact with our platform via our Chrome Extension or who prefer a simpler chat experience. It especially benefits those who want to quickly include supplemental data or files without having to configure a full-scale knowledge base.
The Problem We Solved with This Feature
Previously, adding reference material to chats required it to be absorbed into the global knowledge base, forcing users to manage a large persistent store—even when the references were for a single use. This feature solves that problem by allowing ephemeral attachments:- It streamlines one-off or temporary chats.
- It prevents unnecessary clutter within the knowledge base.
- It improves performance and privacy by not processing attachments for search or indexing beyond their relevant chat thread.
Specific Items Shipped
-
ThreadState now Stores Attachments
The internal data model for a chat thread (ThreadState) has been extended to include an “attachments” field. This addition means that any files or content attached to a chat are stored directly with the conversation context, ensuring that only relevant and immediate attachments are preserved. -
Option to Add Attachments via Prompt
A new field has been added to the Prompt struct along with aWithAttachmentsoption function. With this change, developers can now include attachments when sending a text message prompt. The process is as simple as adding an “attachments” parameter to your API call, making the integration more flexible. -
Attachment Processing within the Token Budget
We introduced anaddAttachmentsmethod that processes attachments alongside other prompt data. This method ensures that attachment content is properly prioritized and accounted for within the overall token budget, so the response generation process remains efficient even when supplemental data is included. -
Modified Prompt Building Flow
The workflow for building a prompt has been updated in the functions responsible for handling knowledge base references (i.e.,knowledgeBase,includeTrainingData, andonlyTrainingDatamethods). They now factor in attachments when constructing the final prompt. This ensures that if attachments are provided, they are integrated optimally without surpassing budget limits. -
Bug Fix in the Knowledge Base Writer
A minor bug previously allowed headers and instructions to be written even when there was no available token budget. This issue has now been corrected, so unnecessary data is no longer appended, which improves prompt efficiency and clarity.
Explain It to Me Like I’m Five
Imagine you’re drawing a picture and you want to add a sticker just for fun. Now, you can stick that sticker on your picture, but it only stays on that picture and doesn’t go into the big book of all your drawings. This way, you can have extra fun with your picture without worrying about cluttering the big book.Technical Details
Under the hood, the chat thread model has been enhanced by extending its state structure to include an array of attachment objects. Each attachment is defined with the following properties:- ID: Generated using our
stidpackage to uniquely identify each attachment. - Title: Can represent the original filename, a document title, or a custom label.
- Source: A string that may denote a filename, URL, or other origin identifier.
- ExtractedContent: The content extracted from the attachment, ideally processed into markdown.
- Size and ContentType: The attachment size (with a per-file limit of 1MB and a total limit of 3MB for a thread) and its MIME type.
- A new field called
attachmentswas added to the Prompt struct. - The
WithAttachmentsoption function allows developers to easily add one or more attachment objects during the creation of a prompt. - The
addAttachmentsmethod is responsible for processing attachment data. It ensures that the content of each attachment is trimmed if necessary (using a preset token budget), validates that required fields (like title, source, and extracted content) are provided and not empty, and automatically rejects or truncates attachments that exceed predefined size limitations. - The methods responsible for constructing the final prompt (which incorporate knowledge base, training data, or a combination thereof) have been modified to “reserve” space within the token budget for the incoming attachment content. This integration guarantees that attachments receive priority when the model constructs the full input for generating a response.
- Finally, any unnecessary addition of header information to the buffer during knowledge base writing (if insufficient budget exists) has been addressed to ensure that the final prompt strictly fits within system constraints.
Enhanced the Prompt ELI5 and Age-Based Explanations
Enhanced the Prompt ELI5 and Age-Based Explanations
Summary
This feature enhances our system’s ability to generate explanation prompts tailored to different audience levels. Originally offering only “explain like I’m five” responses, we have now added options that provide responses in a style suited for middle school and high school audiences. In practice, when a user selects a prompt, our platform uses specialized configurations to generate an explanation at the requested level of complexity. This helps non-technical users, educators, and others quickly obtain explanations that match their understanding.Who we built this for
- Educators, Instructional Designers, and Customer Support Teams: Those who need to communicate complex ideas in simple language.
- Non-technical Users: Individuals, including early learners, who benefit from explanations tailored to their age group.
- Internal Product Teams: Team members (such as Andi Rosca and DROdio) seeking clarity in how the platform adapts explanations based on user requirements.
The problem we solved with this feature
Before this update, our platform only offered one style of explanation (“explain like I’m five”) which did not suit the needs of users requiring different levels of detail. This feature addresses the need for customizable explanation levels, making complex concepts accessible to a broader audience. By tailoring responses to age-specific requirements, we improve overall user experience and ensure that our explanations resonate with the intended audience.Specific items shipped
-
StDropdown Component Update
- Detail: The dropdown component now sets its stacking order (z-index) higher (from 111 to 400) to ensure it is prominently displayed when needed. This minimizes UI conflicts and ensures that pop-up explanations remain visible above other elements.
- Explain it to me like I’m five:
Imagine you have a box of toys. We decided to put this special box on the top shelf so that you can always see it when you need it. - Technical details:
We updated the CSS class string in the StDropdown component (and its item subcomponent) to modify the z-index value. By changing the index from 111 to 400, we ensure that the dropdown view will overlay other elements without interference during animations and visibility toggling.
-
TextSelectionMenu Prompt Enhancements
- Detail: The prompt text in the TextSelectionMenu has been revised. The original message “Explain this to me like I’m five” was updated to “Explain this to me like I’m five years old” for clarity. Additionally, new options have been integrated for middle school (“Explain this to me like I’m in middle school”) and high school (“Explain this to me like I’m in high school”) explanations.
- Explain it to me like I’m five:
Think of it like having different storybooks. Now, if you’re a bit older or need a different kind of story, you have books made just for your age. - Technical details:
In the TextSelectionMenu component, the onSelect event now uses a configuration fromresponsePromptsDatato set the correct prompt based on the user’s selection. Several new cases were added, each mapping to a different explanation style. The event handler calls the appropriate function (explainLikeImTwelveorexplainLikeImSixteen) after retrieving the text input, ensuring that the response reflects a middle school or high school level of explanation.
-
TextUnitV1ActionsBar Enhancements
- Detail: Similar changes were implemented in the TextUnitV1ActionsBar component. Interactive elements now trigger age-specific explanation prompts. Users can choose to have the text explained in a simplified manner for young children or in more advanced terms for older students.
- Explain it to me like I’m five:
Imagine if you could press a button on your computer and get a simple answer or a little more detailed one based on how old you are. It’s like choosing which version of a story you want! - Technical details:
Updates were made to the event handling logic in TextUnitV1ActionsBar. New calls tosubmitPrompthave been added that leverage the enhanced responses fromresponsePromptsData. The component uses conditional logic to direct the input text through either theexplainLikeImTwelveorexplainLikeImSixteentransformation functions, ensuring that the text is correctly formatted for the target audience.
-
Response Prompts Data Configuration Updates
- Detail: We extended the
responsePromptsDataconfiguration to support multiple age-based explanation templates. In addition to the ELI5 template, prompt templates for middle school (explainLikeImTwelve) and high school (explainLikeImSixteen) have been added. These templates include specific instructions to ensure that every generated explanation is tailored to its intended audience. - Explain it to me like I’m five:
It’s like writing different versions of a recipe for making a cake – one for little kids, a more detailed one for older kids, and an even fancier one for teenagers. Everyone gets a recipe that makes sense for them! - Technical details:
TheresponsePromptsDatafile now includes new functions that wrap the input text in detailed instructions. These functions provide layered explanation prompts that guide the response generator on how to elaborate the explanation based on the selected age group. The templates use string interpolation and clearly defined language guidelines to ensure consistency in tone and detail for each audience.
- Detail: We extended the
Updated Homepage Card Order & De‑silo Teams Navigation Link
Updated Homepage Card Order & De‑silo Teams Navigation Link
Summary
This feature revises the homepage experience to improve clarity in showcasing our platform’s use cases. The homepage “hero” section now presents a reordered set of cards that better align with target user roles (e.g. Analysts, Product Managers, Sales, Finance, and Venture Capitalists). In addition, a dedicated “De‑silo Teams” hover link has been added in the navigation area. The “De‑silo Teams” link now features a custom SVG icon (sourced from Webflow) that visually matches the rest of our design system. Together, these changes streamline user access to key product functionalities while enhancing visual consistency.Who we built this for
- End Users by Role:
- Analysts: Receiving a focused “Market Landscape Analysis” card.
- Customer Success Professionals: To help identify churn risks and retention opportunities.
- Product Managers: With prioritized tools like the “AI-Driven PRDs” card.
- Sales and Marketing Teams: With improved visibility of use cases such as “Sales Battlecards” and “Executive Updates”.
- Navigation Users: Those needing a dedicated entry point to the “De‑silo Teams” feature.
The problem we solved with this feature
Before this update, our homepage card order did not effectively communicate the platform’s key use cases, making it difficult for users to quickly grasp which functionalities applied to their roles. Additionally, the navigation did not include a dedicated entry point for the “De‑silo Teams” feature. These issues reduced clarity and user engagement. By reordering the cards and adding a clear, visually consistent “De‑silo Teams” link, we now offer an improved and intuitive user experience.Specific items shipped
-
Navigation Enhancement – New “De‑silo Teams” Hover Link
- Details:
A newHoverLinkcomponent was added to the header navigation. This element directs users to the “De‑silo Teams” section and uses a custom SVG icon imported directly from our Webflow design assets. The SVG, with a viewBox set to “0 0 48 48” and fill set to “currentColor,” guarantees that the icon scales properly and matches the established aesthetics. - Explain it to me like I’m five:
Imagine your favorite storybook—now we put a shiny new button on the cover that shows a pretty picture so you can easily find that special chapter about how friends work together. - Technical details:
In theLandingPageNavbar.tsxfile, we inserted a<HoverLink>with the following properties:href="https://web.storytell.ai/de-silo-teams"icon={icons.deSiloTeams}label="De-silo Teams"
Theicons.deSiloTeamsproperty now contains a new SVG element using the provided SVG path data. The icon’s attributes (such aswidth,height, andviewBox) ensure it is fully responsive and inherits the parent element’s color viafill="currentColor".
- Details:
-
Homepage Use-Case Cards – Reordering & Content Updates
- Details:
TheHeroUseCasescomponent inNewHomePage.tsxwas updated by modifying the underlying data array that drives the display of use-case cards. Several cards have been revised:- The “Analyze a startup pitch deck” card has been replaced with a “Market Landscape Analysis” card for Analysts.
- The churn-risk and retention card now better addresses the needs of Customer Success teams.
- Cards targeting Product Managers, Marketing, Sales, and Finance have been reordered and their titles and descriptions updated to clearly express value. These changes allow the homepage to immediately speak to each user group with a prioritized and contextual message.
- Explain it to me like I’m five:
Think of it like sorting your crayons. Instead of having them all jumbled up, we arranged them in a neat order so that your favorite colors are right on top and easy to pick out. - Technical details:
The reordering was accomplished by editing the array of configuration objects defined in theHeroUseCasesfunction within theNewHomePage.tsxfile. Each card object includes keys such ashref,image,useCase,title, anddescription. For example:-
The initial entry was updated from using the
/use-case/analyze-startup-pitch-deckroute to/use-case/market-landscape-analysiswith theuseCaseproperty set to “Analyst.” -
Similar modifications were made for other objects to adjust the links, images, and messaging.
These changes directly affect how the React components render, ensuring that the homepage accurately represents our strategic priorities and addresses the needs of our target roles.
-
The initial entry was updated from using the
- Details:
Allow up to (30) tabs on an XLS sheet
Allow up to (30) tabs on an XLS sheet
Summary
This feature increases the limit on the number of sheets (tabs) that can be processed from an Excel file. Prior to this change, the system was limited to processing 20 sheets. With this update, users can now upload and process XLS files with up to 30 sheets, addressing a common file upload failure issue reported by users.Who we built this for
- Data analysts and spreadsheet users: Users working with complex Excel files that include multiple sheets benefit by having an increased limit for processing their data.
The problem we solved with this feature
Prior to this update, XLS file uploads that contained more than 20 sheets would fail, causing significant workflow disruptions. By increasing the tab limit to 30, we have resolved the upload issue, ensuring smoother processing of large, multi-sheet Excel files. This matters because it enhances user experience by reducing errors and supporting more complex data files.Specific items shipped
-
Increase Tab Limit:
The maximum number of sheets that the system can process from an Excel file has been increased from 20 to 30. This improvement was implemented by updating the XlsMaxSheets value in the source code, accommodating larger and more complex Excel files. -
Enhanced File Upload Stability:
Alongside the increased sheet limit, diagnostic feedback indicated that while every sheet may have over 1,000 rows, the processing now completes successfully for each sheet. This ensures that even for hefty datasets, the upload process remains robust.
Explain it to me like I’m five
Imagine you have a coloring book with many pages. Before, our program could only look at 20 pages of your coloring book at a time. Now, it can look at 30 pages! This means when you give the program a big coloring book, it can see more pages without getting confused, even though some pages have a lot of pictures.Technical details
The feature was implemented in the Go file located atpkg/go/domains/assets/tabular/xls.go. The key change was updating the constant (initially set to 20) to allow up to 30 sheets. The change directly addresses feedback from DROdio, ensuring that XLS files with many tabs are processed without upload failures, although caution is advised regarding very large sheets (each exceeding 1,000 rows) which could introduce challenges in the summarization stage.Allow spaces when mentioning files or Collections
Allow spaces when mentioning files or Collections
Summary
We have shipped a feature that now allows spaces when using the ”@” trigger to mention assets or Collections in Storytell. This update improves the mention search functionality by correctly handling file names and Collection names that include spaces. Users will experience a more intuitive and error-free mention system, ensuring all relevant assets and Collections appear in search results.Who We Built This For
This update is built for content creators and platform administrators who routinely mention assets or Collections in Storytell. It is particularly beneficial for teams and users that work with files or Collection names containing spaces, ensuring a seamless experience when referencing these items.The Problem We Solved With This Feature:
Previously, the mention functionality would break when assets or Collections had spaces in their names, leading to incomplete search results and user frustration. By allowing spaces, we resolved this issue, ensuring that all assets and Collections are reliably mentioned and accessible, thereby enhancing overall workflow efficiency.Specific Items Shipped:
- **Allow Spaces in Mentions: **Enabled support for spaces when using ”@” to tag assets or Collections, ensuring that file names with spaces are properly recognized.
- **Enhanced Query Matching: **Modified the underlying regex patterns in the MentionsExtension to correctly process multi-word queries, which results in more comprehensive search results.
- **Refined UI Components: **Updated components such as the SearchBar and Mentions rendering to seamlessly integrate the new logic, providing a consistent and user-friendly display across Storytell.
Explained Simply:
Imagine trying to call someone by their full name that contains a space. Previously, Storytell only recognized one part of the name, leading to confusion. Now, it’s like being able to say the whole name correctly so that Storytell can immediately find the right asset or Collection without error.Technical Details:
Technical details: The MentionsExtension in the Mentions.extension.ts file was updated to set the “allowSpaces” flag to true, altering the regex used to capture queries. This change ensures that the search algorithm can accommodate spaces in file names and Collection names. Additionally, adjustments were made in related components like the SearchBar and the Mentions rendering logic to maintain consistent UI behavior. This integrated solution leverages the editor’s reactive owner along with the useWire pattern to deliver accurate and efficient search results within Storytell.Remove Relevancy from Storytell Responses
Remove Relevancy from Storytell Responses
Summary
This feature removes the relevancy filtering from the Storytell. The change simplifies the UI by eliminating the differentiation based on content relevancy, resulting in a more uniform and predictable presentation of information.Who We Built This For
- Content creators and end users: Those who need a clear and unbiased view of their content, without variability introduced by relevancy filters.
- Platform administrators and stakeholders: Users who identified that the relevancy feature was creating confusion and inconsistencies, as highlighted in internal feedback.
The Problem We Solved With This Feature
The relevancy filter was inadvertently obscuring important information by altering the display order and style of content blocks. This led to difficulties in content review and a less consistent user experience. By removing the relevancy aspect, the platform now presents all content uniformly, which aids in clarity and reduces user error.Specific Items Shipped
- Relevancy Logic Removal: The code that evaluated relevancy metrics was removed, eliminating the logic that caused content to be displayed unevenly.
- UI Component Refactoring: Components in the UI were updated to remove any styling or ordering based on relevancy markers, resulting in a cleaner appearance.
- Backend Integration Update: Adjustments were made to the API and data handling processes, ensuring that relevancy attributes are no longer included in the responses sent to the frontend.
Explain It to Me Like I’m Five
Imagine if your teacher said some words were extra important while others weren’t, and it made the page look messy. Now, every word looks the same, so it’s easier to read without any distractions.Technical Details
The removal of relevancy required a comprehensive refactoring of both frontend components and backend data handling. Conditional checks based on relevancy were eliminated from UI components, and the data models were updated to exclude relevancy attributes. This not only simplified the codebase but also improved performance and reduced potential bugs related to mismatched display logic. The changes have been verified with a series of tests to ensure consistent data presentation and UX continuity.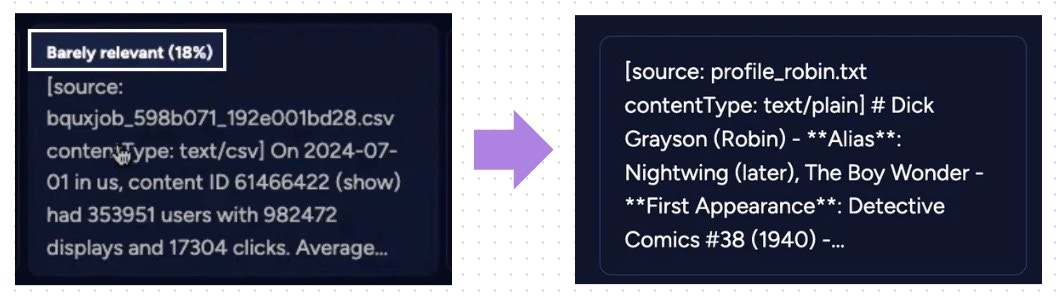
Magic Link Dark Mode UI Text Visibility
Magic Link Dark Mode UI Text Visibility
Summary
This feature improves the visual clarity of text in the Magic Link email interface when viewed on dark mode. By updating color contrasts and style rules, the UI provides a better and more accessible reading experience for users who rely on magic links to log in.Who We Built This For
- Users who prefer dark mode: Particularly those who use dark mode in their applications and value an optimized email interface.
- Accessibility-focused users: Individuals who require high-contrast text for easier reading and better usability.
The Problem We Solved With This Feature
Previously, users struggled to read email content in dark mode due to insufficient text contrast. This made the login process confusing and could lead to misinterpretations of important information. Enhancing text visibility ensures that the login experience is smooth and accessible, thereby increasing overall user satisfaction.Specific Items Shipped
- Contrast Adjustment: The text color and background were updated to have a higher contrast ratio. This enhancement makes the reading content easily legible on dark screens.
- Style Overrides: CSS modifications, including tweaks to autofill focus styles and input fields, were implemented to ensure a consistent visual experience across browsers.
- Accessibility Enhancements: Minor adjustments aligned with modern accessibility standards were introduced to guarantee that all UI elements comply with color contrast requirements.
Explain It to Me Like I’m Five
Imagine you have a coloring book where the words are written in light colors on a very dark page, making them hard to see. We changed the colors so that the words are now bright and clear, making them easy to read.Technical Details
The update involved modifying CSS rules and autofill focus styles in the Magic Link email interface. By increasing the contrast ratios and ensuring consistent application of these styles across different browsers, the feature meets contemporary accessibility standards. The process included cross-browser testing and adjustments for specific autofill behaviors, ensuring robust performance in dark mode environments.
Resize Left Sidebar to Show More Chats
Resize Left Sidebar to Show More Chats
Scroll to Collection when clicking it's breadcrumb
Scroll to Collection when clicking it's breadcrumb
Improved `Not Found` Messaging
Improved `Not Found` Messaging
Summary
This update enhances the “Not Found” screen messaging on Storytell by guiding users towards signing in or signing up. The new message more clearly communicates that the page is restricted due to authentication, helping reduce user confusion. The change is aimed at improving the onboarding experience for new users.Who We Built This For
We built this for newly invited users and all visitors who encounter the Not Found screen. Particularly, it serves users who mistakenly land on restricted pages, clarifying the need to authenticate before accessing content.The Problem We Solved With This Feature
Previously, users encountered a generic “Not Found” message without clear instructions, leading to confusion about access rights. This update remedies that by explicitly indicating that signing in or signing up is the required next step.Specific Items Shipped:
- Guidance Message Update:
Explained Simply:
Imagine you try to open a locked door without a key. Instead of just seeing a locked door, there’s now a sign that tells you exactly where to get the key. That’s what this update does by guiding users towards signing in.Technical Details:
The update modifies the NotFoundScreen component in Storytell. The textual content has been revised to provide explicit instructions, and spacing/layout adjustments have been made to make the message more prominent. These improvements prevent misinterpretation and align the screen’s messaging with Storytell’s overall user experience guidelines.
Add Claude 3.7 to the LLM router
Add Claude 3.7 to the LLM router
Summary
This update introduces Claude 3.7 to Storytell’s LLM router, enhancing the system’s AI capabilities. This integration ensures that Storytell can leverage the latest advancements in language model technology. The new model will provide users with more accurate and contextually relevant responses.- Improved AI Capabilities
- Enhanced response accuracy
Who We Built This For
This feature is beneficial for all Storytell users who rely on accurate and contextually relevant AI-driven insights, particularly content creators and analysts.The Problem We Solved With This Feature:
This integration addresses the need for Storytell to stay current with the latest advancements in LLM technology. By adding Claude 3.7 to the LLM router, Storytell ensures that users benefit from the most up-to-date AI capabilities, improving response accuracy and overall performance. This is vital for maintaining a competitive edge and delivering the best possible user experience.Specific Items Shipped:
- Claude 3.7 Integration: Claude 3.7 has been successfully integrated into Storytell’s LLM router, enabling the system to utilize the new model for generating responses.
Explained Simply:
Think of Claude 3.7 as an upgraded brain for Storytell. By integrating this new model, Storytell becomes smarter and more capable of understanding and responding to your requests accurately. It’s like giving Storytell a boost in intelligence, allowing it to provide better and more relevant information.Technical Details:
The Collections indicate that Claude 3.7 has been added to the LLM router. The integration involved fixing bugs that were occurring around instructions generated by the new model when the trained context was used. The ai packages were updated to include the AnthropicClaude37Sonnet model. The model specifications (AnthropicClaude37SonnetSpec) include details such as ranking, performance, cost, context window (180,000), and maximum output tokens (8,192). The TexterConfig and PromptBuilder components were adjusted to accommodate the new model.Download Markdown Tables as CSV
Download Markdown Tables as CSV
Summary
We shipped an update in Storytell that enables users to export markdown tables as CSV files. With an inline “Download as CSV” button added just below each markdown table, users can now quickly convert table data into a CSV file. This update simplifies data extraction, supports seamless integration with spreadsheet tools, and enhances overall data management within Storytell.Who We Built This For
This feature was built for content creators, analysts, and marketers who frequently use markdown tables. It addresses the need for an efficient method to extract and reuse table data in external applications such as spreadsheets.The Problem We Solved With This Feature:
Previously, users had to manually copy and convert markdown table content before using it in spreadsheets. By automating the CSV conversion directly within Storytell, we eliminate manual errors and save valuable time for users who need to manage table data effectively.Specific Items Shipped:
-
CSV Export Button Integration:
A new inline “Download as CSV” button has been added right below each markdown table. This provides a direct and convenient way for users to trigger the CSV export process without leaving the current context. -
Markdown Table Parsing Logic:
The MarkdownRenderer component now accurately identifies the<thead>and<tbody>sections of markdown tables. It parses header and row data into a structured array, ensuring that all text is properly escaped to conform to CSV standards. -
Seamless Download Mechanism:
The CSV content is generated and encapsulated in a Blob object. A temporary download link is programmatically created and clicked, initiating an automatic download of the CSV file, ensuring a smooth and integrated user experience.
Explained Simply:
Imagine you have a table on your document that you want to use in a spreadsheet, but copying it manually is messy. This update in Storytell adds a button below the table that, when clicked, automatically turns the table into a neatly formatted CSV file. It is like having a tool that effortlessly transforms a printed table into an editable digital version.Technical Details:
Technical details:The feature leverages updates in the MarkdownRenderer component by adding a function that locates the table’s
<thead> and <tbody> elements. It then extracts header cells and row data, mapping them into a string[][] format. Special characters are properly escaped using CSV conventions. The resulting CSV string is wrapped into a Blob with MIME type “text/csv;charset=utf-8”, and a temporary anchor element is generated to programmatically trigger a download, providing a seamless export experience within Storytell.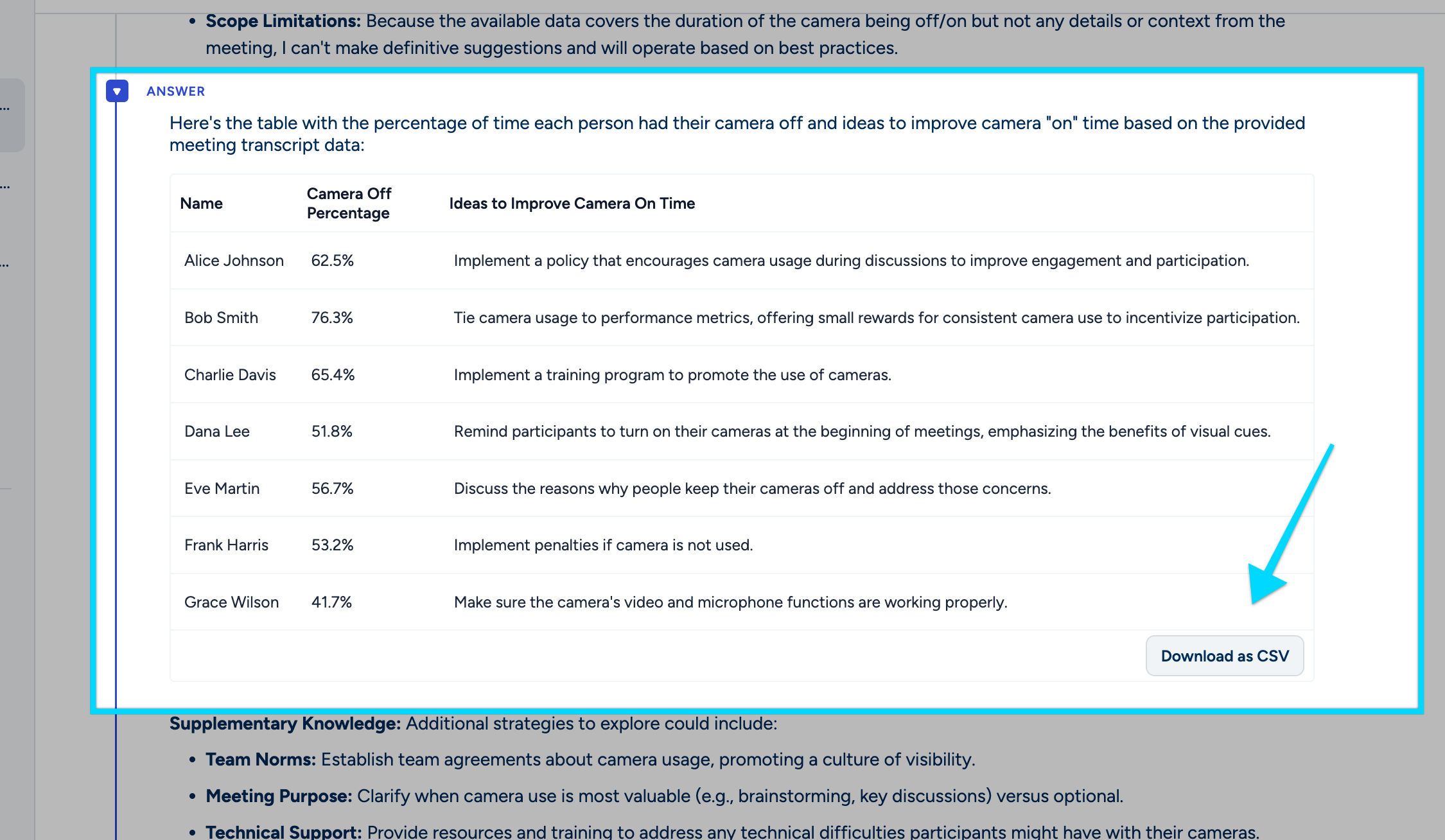
Auto-Scroll for Active Collection in Sidebar
Auto-Scroll for Active Collection in Sidebar
Share Collections based on Email Domain
Share Collections based on Email Domain
Show Breadcrumbs for Collections in the Search Bar
Show Breadcrumbs for Collections in the Search Bar
Improve Performance When Listing Assets Within Collections
Improve Performance When Listing Assets Within Collections
Summary
Improved the performance of listing assets within Collections and added a new endpoint for counting assets. This update significantly reduces the execution time for asset listing queries, especially when dealing with large Collections and introduces a new endpoint that only returns the count of assets to help drive that functionality in the UI.- Optimized the query to list assets within a Collection.
- Added an option to list assets within sub-collections.
- Introduced a new endpoint to return the count of assets.
Who We Built This For
This update is for users who frequently work with Collections containing a large number of assets, as well as UI developers needing to efficiently display asset counts.The Problem We Solved With This Feature
Previously, listing assets within Collections was slow, especially for large Collections or when including sub-collections. This update addresses this performance bottleneck and provides a more efficient way to retrieve asset counts.Specific Items Shipped
- Query Optimization: The query to list assets within a Collection has been revised to improve performance.
- Sub-collection Listing: Added an optional behavior to list assets within sub-collections.
- Asset Count Endpoint: Introduced a new endpoint that only returns the count of assets.
Explained Simply
Imagine you have a giant filing cabinet with lots of folders and papers. This feature is like hiring a faster worker to find and count the files you need, so you don’t have to wait as long.Technical Details
- The query in
services/controlplane/domains/curator/collectionsSQL/asset_col_queries.sqlsqlc.generated.gohas been optimized. - A new endpoint,
GetCountAssetsByCollectionID, has been added inservices/controlplane/endpoint_collection_get_count_assets_by_collection_id.go. - The
GetAssetsByCollectionIDfunction inservices/controlplane/domains/curator/curator_core_get_assoc_assets.gowas modified to include sub-collections based on theIncludeSubCollectionsparameter. - Execution time has decreased by 3x (2.734ms vs 0.895ms) with the new query plan.
- Planning time has increased (14.674ms vs 8.021ms), but is negligible since it happens only once.
Batch Upload Websites
Batch Upload Websites
Summary
Adding multiple websites to your Collections just got easier. The new web scraper enhancement lets you input several URLs at once, streamlining your content ingestion process. This update saves time and simplifies the initial setup of Collections with web-based data.- Add up to 10 URLs in a single screen.
- Simplified workflow for ingesting web content.
Who We Built This For
This feature is designed for content curators, researchers, and knowledge managers who regularly incorporate web-based information into their Collections.The Problem We Solved
Previously, adding multiple websites was a time-consuming process. Users had to add each URL individually. This feature improves efficiency.Specific Items Shipped
- ”+ Add More” Button: A new button allows users to input multiple URLs on a single screen, up to a limit of 10.
- Batch URL Input: Users can now paste multiple URLs into the input field, separated by spaces, commas, or semicolons.
Explained Simply
Imagine you’re making a playlist, but instead of adding one song at a time, you can add a whole bunch at once. This feature lets you add multiple website links to your Storytell Collections. Instead of adding websites one by one, this feature lets you add up to 10 at once, saving you a lot of time and effort.Technical Details
The implementation is currently FE only, with plans to move it to the BE for background processing and status updates. The FE implementation avoids complex DB transactions and asset uploads. The componentWebContentUpload.tsx has been modified to allow for multiple URL inputs. The CrawlURL function in the client API is used to initiate the scraping process for each URL.
Search for Collections and Assets
Search for Collections and Assets
Summary
A new Search Functionality has been shipped in Storytell. This update allows users to quickly launch a search bar using ⌘ + / (Mac) / Ctrl + / (Windows), dynamically fetches Collections and Assets, and automatically highlights selected assets for better visibility. Users can now navigate directly to a Collection or asset with minimal effort.- Keyboard Shortcut ⌘ + / (Mac) / Ctrl + / (Windows) to instantly open the search bar
- Real-time filtering and organization of Collections and Assets
- Automatic asset highlighting upon selection
Who We Built This For
This feature is designed for Collection managers, administrators, and power users who need rapid access to specific Collections and Assets. It addresses the needs of users handling large datasets who require efficient navigation and content retrieval.The Problem We Solved With This Feature
Before this update, users had to manually scroll through lengthy lists of Collections and Assets. This update eliminates time-consuming navigation, reducing user effort while enhancing workflow efficiency.Specific Items Shipped
- Keyboard Shortcut Activation:
The search bar can now be opened instantly using ⌘ + / (Mac) / Ctrl + / (Windows), providing immediate access to search functionalities. - Dynamic Search Results:
Collections and Assets are filtered dynamically as the user types, ensuring that results are relevant and updated in real time. - Asset Highlighting & Navigation:
Once an asset is selected from the search results, the interface scrolls to it and highlights it for easy identification, improving visual tracking.
Explained Simply
Imagine needing to find a book in a huge library. With this update, you simply press a shortcut, type in what you’re looking for, and the system immediately shows you the exact shelf and book you need. It saves time and makes your search as effortless as using a smartphone’s search feature.Technical Details
This feature leverages a newly developed SearchBar component built using Solid-JS. It listens for specific keyboard events to trigger the search interface. The search functionality is powered by real-time API calls (via the searchAssetsAndCollections function), which dynamically retrieve and filter the data, while smooth scrolling and DOM manipulation ensure that selected assets are visually highlighted.Storytell Response Breakdown
Storytell Response Breakdown
Summary
This feature enhances Storytell by exposing the model’s internal reasoning behind its answers. It introduces a dedicated section that presents the reasoning in a clearly formatted display, making it easier to understand how responses are derived. Key updates include new visual cues for the reasoning section and the ability to collapse/expand the reasoning details. The change is user-friendly, providing transparency in an elegant and accessible format.Who We Built This For:
This feature is built for advanced users and power users who want to gain deeper insights into the answer generation process. Users who need to validate the reasoning behind responses for research or debugging purposes will particularly benefit from this update.The Problem We Solved with This Feature:
Many users found it challenging to understand how Storytell arrives at its answers. By revealing the hidden reasoning steps, we address the opacity of the process and offer greater transparency. This improvement empowers users with a better understanding of the logic behind responses, making the technology more trustworthy and debuggable.Specific Items Shipped:
- Reasoning Section UI Update: Introduced a new UI component that displays the model’s internal reasoning with a clear, collapsible section. This section is formatted in lighter grey for easy distinction from the final answer.
- Copy Button Functionality: Added functionality allowing users to copy both the question and the full response (reasoning plus answer) or just the answer, enhancing usability.
- Enhanced Formatting: Ensured the reasoning is displayed in a structured format (using designated section tags) so that it’s consistently readable and accessible across different devices.
Explained Simply:
Imagine reading a detailed explanation of how a math problem is solved – this feature gives you that insight for every answer in Storytell. It shows you the thought process step-by-step, just like seeing the scratch work behind a finished homework problem. This makes it easier to trust and understand the results provided.Technical Details:
Technical improvements include enabling a new set of front-end components that parse and render the reasoning sections from model responses. The system detects XML-like markers (e.g.,[[[Reasoning]]]) and applies specific styling rules to display them in a collapsible format. This feature relies on efficient client-side processing to toggle visibility without impacting overall performance.
Delete SmartChats™
Delete SmartChats™
Summary
This feature offers an intuitive interface within Storytell for deleting SmartChats™ from a Collection. It provides a clearly labeled delete option directly on the SmartChat™ list, simplifying the process. Key updates include a responsive delete action, confirmation modals, and enhanced accessibility features. The update empowers users with efficient management of their SmartChats™.Who We Built This For:
This update is designed for users managing Collections who need to organize or remove obsolete or unwanted SmartChats™ quickly. It is particularly useful for power users and administrators keen on maintaining a clean workspace and managing content effectively.The Problem We Solved with This Feature:
Previously, users had difficulty in managing and deleting outdated SmartChats™, which often cluttered their Collections. By introducing a dedicated UI for deletion, Storytell addresses this issue, reducing friction and preventing accidental removals. It improves the user workflow by offering a clear, easily accessible deletion option.Specific Items Shipped:
- Delete SmartChat™ Button: Implemented a clearly visible delete button next to each SmartChat™, ensuring users can easily identify and access the delete function.
- Confirmation Modal: Developed a confirmation modal to double-check user intent before a SmartChat™ is removed, minimizing accidental deletions.
- Responsive UI Enhancements: Optimized the UI layout for different devices, ensuring that deletion actions are seamless and intuitive across all screen sizes.
Explained Simply:
Think of it like tidying up an email inbox; this feature lets you quickly remove a conversation you no longer need. It adds a trash button to each SmartChat™ in your Collection, and when you click it, a pop-up asks if you’re sure you want to delete it. This makes managing your chats as easy as cleaning up your desk.Technical Details:
The implementation leverages modern front-end frameworks to bind delete actions directly to the SmartChat™ UI components. When a user initiates a delete request, a function interfaces with Storytell’s back-end to mark the specified SmartChat™ as removed. The process employs asynchronous calls to ensure the UI remains responsive, and state management is updated in real-time to reflect the deletion across the Collection. Advanced accessibility features ensure that confirmation modals are navigable via keyboard and screen readers.Enhanced `Improve It` User Experience
Enhanced `Improve It` User Experience
Summary
The Improve It button has been enhanced to provide a more engaging and user-friendly experience. This update includes visual enhancements and a regenerate button for refining prompts.Who We Built This For:
- Users seeking to optimize their prompts for better results.
- Users who want a more intuitive and visually appealing prompt improvement process.
The Problem We Solved:
We aimed to enhance user engagement with the “Improve It” feature by making it more visually appealing and providing users with more control over prompt refinement.Specific Items Shipped:
- Light Bulb Icon on the Improve It Modal: Added a light bulb icon to the “Improve It” modal to enhance visual appeal.
- Updated Copy: Updated the copy within the modal to be more user-friendly and informative.
- Light Bulb Icon on the Results Page: Included a light bulb icon on the title of the results page for visual consistency.
- Regenerate Button: Added a regenerate button to allow users to refine prompts and generate new suggestions, with a short bold summary sentence.
Explained Simply:
Imagine you’re writing an essay, and you want to make it even better. The “Improve It” button is like having a helpful friend who gives you suggestions. We’ve made this friend more visually appealing and easier to use. Now, this friend uses a lightbulb icon and shows it on the results page too. We’ve also added a “Regenerate” button so you can ask for even more ideas to make your essay shine.Technical Details:
- Modified CSS to include a light bulb icon and update the text in the “Improve It” modal
- Added a regenerate button that calls the enhance prompt API.

LLM Response Timeout Management
LLM Response Timeout Management
Summary
Added timeout controls for LLM (Large Language Model) calls to prevent hanging responses and improve user experience. This update implements a 60-second timeout for model responses and 5-second timeout for categorization calls.Who We Built This For:
- Users interacting with AI models
- Platform administrators managing system reliability
- Enterprise users requiring predictable response times
The Problem We Solved:
Addressed the issue of prompts “hanging” or “freezing” due to long responses that never finish, improving system reliability and user experience by ensuring predictable response times.Specific Items Shipped:
- Context Timeout Implementation: Added 60-second timeout for LLM context calls
- Categorization Timeout: Implemented 5-second timeout for prompt categorization
- Global Timeout Controls: Added timeout controls across all LLM providers (Anthropic, OpenAI, Gemini, Groq)
Explained Simply:
Think of asking a question to an AI as making a phone call. Sometimes, the AI might take too long to respond - like being put on hold forever. We’ve added a timer that automatically ends the call if it takes too long, so you’re not left waiting indefinitely. It’s like having a reasonable time limit on how long you’ll wait for an answer.Technical Details:
- Implemented
context.WithTimeoutwith 60-second duration for main LLM calls - Added 5-second timeout for categorization and complexity assessment calls
- Applied timeouts across all LLM providers including Anthropic, OpenAI, Gemini, and Groq
- Implemented proper context cancellation and cleanup using
defer cancel() - Added timeout handling in the model router for prompt categorization
Add Llama and DeepSeek Models to the LLM router
Add Llama and DeepSeek Models to the LLM router
Summary
Storytell now integrates both Deepseek R1 and Llama models in an enterprise-safe environment. Hosted on secure US-based infrastructure, these integrations enhance AI reasoning and natural language processing capabilities while ensuring strict data compliance. Users can manually select either model by appendingUse Deepseek or Use Llama to their queries, though neither is yet embedded in the LLM router. Check this page on how to manually override the LLM routerWho We Built This For
- Enterprise Teams: Organizations requiring cutting-edge AI capabilities while adhering to strict data security and compliance standards.
- Developers & Engineers: Professionals needing advanced AI assistance for coding, debugging, and structured problem-solving.
- Researchers: Users who benefit from logic-driven queries and complex computations.
The Problem We Solved
We addressed the need for a secure, enterprise-grade AI solution that delivers advanced reasoning and computation. Traditional AI tools often lack the necessary security measures for sensitive applications, and open-source models may expose data risks. This integration provides a privacy-safe, compliance-focused alternative.Specific Items Shipped
- Deepseek R1 Integration:
Storytell now supports Deepseek R1, enabling advanced reasoning and problem-solving capabilities. - Llama Integration:
Storytell now supports Llama, providing versatile natural language understanding and generation capabilities. - Manual Model Selection:
Users can explicitly invoke Deepseek R1 by addingUse Deepseekor Llama by addingUse Llamato their prompts. - Enterprise-Grade Security:
Both models are hosted on secure, US-based infrastructure, ensuring compliance with data privacy regulations. - Current Limitations:
Neither Deepseek R1 nor Llama is yet embedded in the LLM router and must be manually selected.
Explained Simply
Imagine you’re working on a complex math problem or trying to write a detailed report. Deepseek R1 is like a super-smart helper that can handle these tasks more effectively than most AI tools. Llama, on the other hand, is like a versatile assistant that excels at understanding and generating human-like text. Both helpers are hosted in highly secure environments, like safes, so your data stays protected.Technical Details
- Integration Approach: Both Deepseek R1 and Llama are integrated as standalone models, allowing manual invocation via their respective keywords (
Use DeepseekandUse Llama). - Hosting: Both models are deployed on secure, US-based servers to meet enterprise compliance requirements.
- Functionality:
- Deepseek R1 excels at reasoning-heavy tasks, advanced computations, and structured problem-solving.
- Llama provides versatile natural language understanding and generation capabilities.
- Limitations:
- Neither model is currently embedded in the LLM router.
- Users must manually select the desired model for each query.
Mention Collections and Files
Mention Collections and Files
Summary
This feature enables users to mention Collections and files within Storytell simply by typing ”@“—in a manner similar to how Linear handles mentions. When a user types ”@”, our interface now displays structured suggestions divided into sections (Collections and Files). This not only streamlines the user experience but also reduces ambiguity when interacting with data references in prompts.Who We Built This For
We built this feature for users who work heavily with Collections and file references, particularly teams needing to quickly and accurately reference these entities in their workflow. The targeted use cases include:- Users who need to compose queries like “Tell me what files are in my @collection/abc” or “Compare @collection/abc to @collection/xyz” without any confusion.
- Teams relying on clear textual references to link Collections or files directly within our chat or command context.
The Problem We Solved With This Feature
Previously, users were limited by a lack of an intuitive system for referencing collections and files; all references had to be entered manually, increasing the risk of typos and misinterpretation by our backend processes. This feature addresses the following issues:- It removes the ambiguity of manually typed references.
- It ensures our backend can detect and process these references reliably via an integrated lexer.
- By structurally integrating references, LLMs receive cleaner prompts, leading to more accurate responses and improved workflow efficiency.
Specific Items Shipped
-
@ Mention Parsing
- Summary: Implemented robust ”@ mention” parsing for Collections and files.
- Details: The interface now detects when users type ”@” and presents suggestions for Collections and files, divided into clear sections. This mimics the familiar behavior found in platforms like Linear, enhancing user productivity and reducing input errors.
- Explain it to me like I’m five: Imagine you’re writing a note about your favorite toys, and when you type ”@” it magically shows you a list of all your toys so you can pick the right one to talk about.
- Technical details: On the frontend, event listeners intercept ”@” keystrokes to trigger a dropdown menu with categorized suggestions. The suggestion list dynamically filters potential matches based on the user’s input. This is seamlessly tied into our backend services via a lexer that extracts and normalizes these mentions for further processing.
-
UI Enhancements for Mention Display
- Summary: Upgraded our UI components to support and display mention suggestions effectively.
- Details: Several UI components have been updated, including asset tables and modals, to incorporate the visual and interactive elements necessary for the new mention feature. This ensures that users see a seamless experience from both the insertion and display perspectives.
- Explain it to me like I’m five: It’s like getting a big, colorful sticker next to every toy name so you can tell them apart easily!
- Technical details: Changes include modifications to file asset renderers (e.g., determining mime types based on file names), updates to component styling for mention elements, and enhanced support for single-click activation of a mention. These refinements ensure that the feature integrates cohesively with existing workflows and maintains consistency in user interface behavior.
New Signup and Login Page
New Signup and Login Page
Explain it to me like I’m five
Imagine you had a favorite game that got a shiny new cover. Now the buttons on the game box point exactly where you need to go to start playing. That’s what we did here – we made it super clear where to click for signing up or logging in, so everyone can start having fun easily.Summary
We’ve updated the signup and login pages on our website to match the new homepage design and streamline the user authentication process. These pages now feature new CTA links, refined messaging, and reliable event tracking (via PostHog) to guarantee a smooth experience when users sign up or log in.Who we built this for
- New Users: Making it easier to sign up with clear instructions and a modern layout.
- Existing Users: Providing a consistent, updated login experience.
- Analytics Teams: Ensuring proper event tracking such as sign_up_started, sign_up_successful, and log_in_started.
The problem we solved with this feature
Our old authentication pages were mismatched with the new design language of the website, causing confusion and inconsistent user experience. This update reinforces our brand identity, simplifies navigation (by ensuring links point to the correct pages), and maintains accurate event tracking across the authentication flows.Specific items shipped:
-
Updated Signup Page:
We redesigned the signup page to include a clear “Already have an account?” link that now correctly routes users to https://storytell.ai/auth/login. PostHog events such as sign_up_started are integrated to properly monitor user registration events. -
Updated Login Page:
The login page now displays a refreshed “Don’t have an account?” link directing users to https://storytell.ai/auth/signup. The page supports magic link email functionality, ensuring users have a seamless, password-free login experience while tracking events like log_in_started. -
Comprehensive Testing and Validation:
The changes were tested in our dev environment to verify that magic link emails, CTA interactions, and event tracking are functioning as intended, ensuring a smooth transition when the changes go live.
Technical details
The update leverages our existing frontend components, replacing outdated UI elements with updated versions matching the new homepage aesthetics. Routing was adjusted so that the “Already have an account?” CTA on the signup page points to the login route and vice‑versa, ensuring proper navigation. We verified that our PostHog analytics (tracking events such as sign_up_started, sign_up_successful, and log_in_started) are firing correctly. Comprehensive testing (both automated and manual) was conducted to ensure that magic link email functionality remains intact in both dev and production environments.New Collection Screen Layout
New Collection Screen Layout
Explain it to me like I’m five
Think of your school locker where every important thing—your books, your toys, and your drawing pad—has its own special place, all arranged neatly. This update makes sure that whether you want to chat or look at pictures, everything you need is always right there, so you never have to search hard for your things.Summary
This update introduces a persistent Chat tab and a restructured Collections Dashboard that provides three fixed tabs, including a new chat section. With a prompt bar at the top and an integrated view for both chats and assets, users have instant access to recent conversations and related content.Who we built this for
- Collection Managers: Users who interact with Collections and need fast access to communications and assets.
- Proactive Users: Those who want a seamless experience navigating between chat conversations and assets.
- Stephen and Similar Users: Users who proposed and will benefit from the persistent navigation structure.
The problem we solved with this feature
Previously, users struggled to quickly access chats and assets within a Collection, leading to a disjointed navigation experience. This update reduces context switching by introducing persistent tabs, ensuring users have quick and continuous access to essential features.Specific items shipped:
-
Persistent Chat Tab:
A new “Chat” tab now remains visible across all Collection views. This allows users to immediately access discussion threads related to each Collection without having to navigate away from the page. -
Unified Collections Dashboard:
The dashboard has been restructured to feature three persistent tabs – including chat and asset views – with a prompt bar fixed at the top. The interface now includes a recent chats card with filtering options and a “see all” button that opens a dedicated chat drawer. -
UI Enhancements for Consistency:
The overall layout now displays assets from sub-folders more cohesively, while the persistent tabs ensure a unified navigation experience across the platform.
Technical details
The dashboard was revised using our SolidJS component architecture to support three persistent tabs. The new Chat tab integrates with our threads API and maintains state through the UI context, ensuring it remains visible when navigating across Colections. A fixed prompt bar allows easy user input, while updated routing ensures the “see all” button correctly opens the chat drawer. Additionally, improved CSS styling and state management updates enhance the responsiveness and layout consistency of asset and chat displays.Onboard Gemini 2.0 Flash model from Google
Onboard Gemini 2.0 Flash model from Google
Explain It to Me Like I’m Five
Imagine you have a super-fast, smart robot friend who can answer your questions almost instantly! It listens, thinks, and replies super quickly. But, just like learning a new game, sometimes it makes mistakes. We’re helping it get even better over time.Summary
We’ve onboarded the Gemini 2.0 Flash model from Google, a newly released AI model designed to enhance AI-driven interactions within Storytell. This integration aims to provide faster, more contextually aware responses, improving overall user experience. However, certain limitations should be considered to ensure optimal performance.Technical Details
Model Integration
The Gemini 2.0 Flash model has been seamlessly integrated into our infrastructure, enabling real-time interactions via API.Data Handling
- The model processes incoming data dynamically, ensuring responsiveness to user queries.
- Routing Mechanisms: Since external ranking scores influence response selection, maintaining accuracy requires careful data handling.
Testing and Debugging
- Initial testing has been conducted, but due to the model’s novelty, unforeseen issues may arise.
- Further testing is necessary to refine edge cases and optimize performance.
Specific Items Shipped
- Model Interface Established – We created a way for our system to communicate with Gemini 2.0 Flash.
- Routing Control Using External Data – We leverage external ranking mechanisms to enhance response accuracy.
- Initial Testing Conducted – The model has undergone preliminary testing to ensure smooth functionality in most scenarios.
The Problem We Solved With This Feature
The integration of Gemini 2.0 Flash addresses the need for faster, smarter AI-driven interactions within Storytell. This upgrade enhances user experiences by delivering responses that are more natural, insightful, and efficient.Who We Built This For
This feature is designed for:- Developers & Businesses using AI for customer support, content creation, or interactive applications.
- Tech Enthusiasts eager to experiment with the latest AI advancements to push the boundaries of AI-driven interactions.
One-click `Improve It` Button
One-click `Improve It` Button
Onboard o3-mini Model from OpenAI
Onboard o3-mini Model from OpenAI
Summary
The newly shipped feature involves onboarding the o3-mini model from OpenAI, a recently released model designed to enhance AI capabilities on Storytell. This feature allows integration with the latest AI model, potentially improving user interaction with our system. However, there are some caveats that need to be considered to ensure the model’s optimal performance.Technical Details
The o3-mini model from OpenAI operates as a cutting-edge machine learning model. Integration involves several key technical aspects:- Model Integration: The o3-mini model has been seamlessly integrated into our existing infrastructure. This involves interfacing with the model’s API to facilitate real-time interactions.
- Data Handling: The model processes incoming data, which necessitates efficient routing mechanisms. Given the reliance on external ranking scores for optimal routing, a lack of control over this data could lead to inaccuracies.
- Testing and Debugging: Thorough testing is required to identify potential bugs. Due to the novelty of the model, it hasn’t been tested across all possible scenarios, and unforeseen issues may arise.
Explain It to Me Like I’m Five
Imagine you got a cool, new toy robot that can talk and think. This robot can learn new things and help you answer questions or tell stories. However, sometimes it might not know everything yet, so it might need more time to learn the right answers. We’re still figuring out how to make it work perfectly, like teaching a puppy how to fetch.Specific Items Shipped
- Model Interface Established: We created a way for our system to talk to the o3-mini model using its special language tools.
- Routing Control Using External Data: We use external scores to help decide the best way for the model to handle conversations. This helps make sure you get the smartest answers back.
- Initial Testing Conducted: Although all scenarios haven’t been covered, the model has gone through preliminary testing phases to catch initial errors and help it run smoothly in most situations.
The Problem We Solved With This Feature
This feature addresses the need for integrating advanced AI capabilities, thereby enhancing Storytell’s interaction quality. The o3-mini model provides more sophisticated AI responses, improving user experiences by making them more natural and intuitive. It’s crucial as it keeps us competitive in AI-driven technology.Who We Built This For
This feature has been designed for developers and businesses that leverage AI for customer support, content creation, or any application requiring advanced interaction capabilities. It also serves innovative tech enthusiasts eager to experiment with the latest in AI technology, giving them the tools to explore new use cases and possibilities.Ability to Edit and Delete Assets
Ability to Edit and Delete Assets
Summary
This feature gives users the ability to update asset display names and summaries and also lets them delete assets when needed. When an asset or an entire Collection is deleted, the deletion is performed in Clickhouse as well to ensure consistency between systems.Technical details
- Front-end Changes:
- Updated components such as
CollectionAssetTable,EditAssetModal, andDeleteAssetModalthat provide users with interfaces to edit asset details or delete assets. - New modals are triggered by user actions allowing for confirmation and data input.
- Updated components such as
- Back-end Enhancements:
- The back-end service now handles updates and deletions by removing asset records from both primary storage and Clickhouse.
- Ensures that deletions are propagated to all relevant systems to maintain data integrity.
- UI/UX Improvements:
- Updated CSS and layout modifications ensure that the new functionalities are intuitive, responsive, and consistent across different devices.
Explain it to me like I’m five
Imagine you have a scrapbook with lots of pictures. Sometimes you want to change the title on one of your pictures, or maybe you decide you don’t want a picture anymore and tear it out of your scrapbook. This update gives you a simple way to change the picture names or remove them completely, so your scrapbook always looks neat and updated—even if you have a giant backup book keeping all your pictures safe.Specific items shipped
-
Ability to Edit Assets:
Users can now click on an asset to update its display name and summary. The interface opens an edit modal where changes are sent to the back-end service, which then confirms success by updating the asset’s records. -
Asset Deletion with Confirmation:
A new delete asset option has been added. When a user deletes an asset, it not only removes it from the interface but also from Clickhouse if the whole Collection or an individual asset is being deleted. The process confirms deletion via a modal to avoid accidental removal. -
User Interface Enhancements:
Changes in components such asCollectionAssetTableand related CSS ensure that the new editing and deletion buttons are well integrated into the existing design, making it intuitive and responsive on various devices.
The problem we solved with this feature
Users needed a simple and reliable way to manage their assets—being able to update what is displayed and completely remove assets that are no longer needed. Before this update, there was no straightforward mechanism to change asset display names or summaries, nor to ensure that deletions were correctly reflected in related systems like Clickhouse. This improvement reduces clutter, prevents confusion, and enhances the overall user experience.Who we built this for
This feature was built for users who manage digital assets—such as content creators, asset managers, and system administrators. It addresses the need for better organization and control of assets by allowing them to easily rename or delete items and ensuring that these changes are synchronized across all systems.Manage and Control Access for Collections and Chats
Manage and Control Access for Collections and Chats
Summary
We’ve successfully launched a feature that allows users to share Collections and chats. Check out our documentation here. This feature introduces a robust information architecture that allows users to manage permissions for individual entities or collections of entities effectively. It empowers Organization Admins and Collaborators to control access to Collections and Threads, enabling a more organized and secure way to handle assets and knowledge within Storytell.Technical Details
The Collections, Permissions, and Entitlements feature is designed to provide granular control over user access within an organization. Here’s a deep dive into its technical components:- Collections Control Plane: Establishes the foundational structure for creating, reading, updating, and deleting Collections. It ensures that root Collections are protected from accidental deletions and allows assets and threads to be managed within these Collections.
- Authorization Mechanism: Implements a flexible permission system where Collaborators can grant or revoke access at both the Collection and Thread levels. This includes handling different user types such as Registered Users, Guests, and Pending Users, ensuring that access is correctly managed based on user roles and organization policies.
- API Integrations: Ensures that threads and assets are implicitly added to personal Collections if they are removed from all others. Additionally, it purges threads and assets from Collections upon deletion unless they exist in another Collection, maintaining data integrity.
- Operational Tooling: Provides tools for Storytell Operators to export user Collections, assets, and permissions to external platforms like Google Sheets. This facilitates support and auditing processes by allowing easy access to user-specific data.
- Permission Evaluation: Implements efficient algorithms to evaluate permissions within 100ms, ensuring a responsive user experience. The system prioritizes higher-level permissions in case of conflicts and handles permission inheritance and overrides to maintain consistent access control.
- User and Team Management: Allows Organization Admins to manage user roles and team permissions effectively. This includes creating, updating, and deleting teams, as well as granting or revoking access for teams to specific Collections and SmartChats™.
Explain it to me like I’m five
Imagine you have a big toy box (Collections) with different compartments (Threads) for your toys. With our new feature, you can decide who gets to play with which toys. If you’re in charge (Organization Admin), you can say, “Johnny can play with the cars,” or “Sally can access the dolls.” This way, everyone knows exactly which toys they can play with, and you keep everything organized and safe.Specific Items Shipped
- Create, Read, Update, and Delete Collections: Allows users to manage Collections by adding, viewing, modifying, or removing them as needed.
- Prevent Deleting Root Collections: Ensures that primary Collections cannot be accidentally deleted, protecting the core structure.
- Upload Assets into a Collection: Enables users to add individual assets, like documents or files, into specific Collections.
- Add Existing Assets to a Collection: Allows users to organize already existing assets by assigning them to different Collections.
- Create Threads Directly in a Collection: Facilitates the creation of new threads within a selected Collection for better organization.
- Grant or Revoke Collaborator Access: Provides mechanisms for Collaborators to manage user access to Collections and threads, including inviting new users via email or shared links.
- Organization Admin Role Management: Allows admins to assign or revoke the Organization Admin role to ensure proper access control within the organization.
The Problem We Solved with This Feature
Before implementing Collections, Permissions, and Entitlements, managing access to various assets and knowledge within an organization was cumbersome and lacked flexibility. Users struggled with organizing their content effectively, leading to potential security risks and inefficiencies. By introducing a structured permission system, we address the need for precise access control, ensuring that only authorized users can access specific Collections or threads. This enhancement not only improves security but also streamlines the workflow, making it easier for organizations to manage their information architecture comprehensively.Who We Built This For
We designed the Collections, Permissions, and Entitlements feature for Organization Admins and Collaborators who need to manage and oversee access to various assets and knowledge within their teams. Specific use cases include:- Enterprise Teams: Managing access to sensitive documents and projects within large organizations.
- Project Managers: Organizing project-specific threads and ensuring that only relevant team members have access.
- Support Teams: Quickly exporting user permissions and Collections to address support queries efficiently.
Ability to download the original file from Stored Assets
Ability to download the original file from Stored Assets
Summary
This feature allows users to download a file directly from Storytell. When a user clicks on a file, they will be able to see the raw content of the file. Instead of displaying this content in a pop-up modal with a markdown version, the implementation now focuses on providing a direct download from a cloud storage URL. Here’s the documentation on how to do thisTechnical details
The implementation of this feature involves creating endpoints for both markdown rendering and signed URLs. When the user clicks on a file, the application will generate a signed URL that grants temporary access to the raw content stored in the cloud. This is achieved by integrating the cloud storage API to facilitate smooth and secure file downloading.-
Endpoint Creation: We set up two endpoints:
- One for handling markdown rendering.
- Another for providing signed URLs for direct content access.
- Security Protocol: The signed URL ensures that the files are accessible only for a limited time, providing an additional layer of security and protecting against unauthorized access.
- User Experience: The user simply clicks on the file link, which triggers the application to provide the download link, ensuring a seamless experience without unnecessary pop-ups.
Explain it to me like I’m five
Imagine you have a really cool drawing that you want to share with your friend. Instead of showing it to them on your phone or computer where they can’t touch it, you just let them take it home. When you click on the drawing, it doesn’t go on the screen; instead, it gets sent directly to them, so they can keep it forever. That’s exactly what we’ve done here—now when someone clicks on a file, they get to download it right away!Specific items shipped:
-
Direct File Download:
- Users can click on a file link to download the actual file instead of viewing it in a pop-up. This streamlines the process and reduces user distractions.
-
Signed URL Generation:
- The system generates a temporary link that allows users to access their files securely. This URL ensures that only authorized users can view or download the files, maintaining data security.
-
Endpoint Setup:
- We’ve put in place specific endpoints to manage file access. One allows users to view markdown content, and the other gives them a quick link to download files directly.
The problem we solved with this feature
Before this feature was implemented, users had to view files in a modal pop-up, which could be an inconvenient experience. Users expressed a need for a simpler way to access and download files directly without the hassle of navigating through additional views. By enabling direct downloads, we improved user experience, allowing for quicker access to important documents and enhancing overall functionality.Who we built this for
This feature was built primarily for content creators and end-users who frequently need to download files for offline use or sharing. Specifically, it addresses:- Content Creators: Who need to provide raw data or documents to others easily.
- End-Users: Who prefer quick access to downloadable content rather than having to view it in a pop-up and then navigate away to download it.
Users we especially built file downloads for
- Brandon from Siemens
Replicate the Storytell Website Home Page to Storytell.ai
Replicate the Storytell Website Home Page to Storytell.ai
Summary
We have successfully replicated the Web home page design onto the Storytell.ai web app. This feature includes significant enhancements, such as integrating a prompt bar and an animated graphic that replaces the product screenshot.Technical Details
The replication process involved several technical steps to ensure the new design elements were effectively integrated into the Storytell.ai web app. The key technical components include:- Prompt Bar Integration: The prompt bar is a critical feature allowing users to interact directly with the product from the homepage. It was implemented to be persistent, ensuring it remains accessible even when outside the user’s viewport. This required carefully considering the app’s layout and user interface design to maintain functionality across different screen sizes and devices.
- Animation Replacement: The product screenshot in the “How Storytell turns data into insights” section was replaced with an animation. This animation dynamically demonstrates the product’s capabilities, providing a more engaging and informative user experience. The technical challenge was to ensure smooth animation performance without affecting the app’s load time.
- Responsive Design Adjustments: The new homepage design required adjustments to ensure responsiveness across various devices. This involved using CSS media queries and JavaScript to adapt the layout and functionality based on the user’s device and screen size.
Explain it to Me Like I’m Five
Imagine you have a cool new toy and want to show it to your friends. Instead of just telling them about it, you create a fun and colorful picture that shows exactly how the toy works. That’s what we did with our website! We made it look super cool and added a special button that immediately lets people play with our toy (the app). It’s like having a magic door that takes you straight to the fun part!Specific Items Shipped
-
Prompt Bar Integration:
We added a special bar at the top of the page that lets users start using our app right away. This bar stays in place even if you scroll down, so it’s always easy to find. -
Animation Replacement:
Instead of a boring picture, we now have a moving animation that shows how our app works. This makes it easier for people to understand what we do and why it’s awesome. -
Responsive Design Adjustments:
We ensured our website looks great on any device, whether a phone, tablet, or computer. This means everyone can enjoy the new design no matter how they visit our site.
The Problem We Solved with This Feature
The primary problem we addressed with this feature was the need to enhance user engagement and streamline the transition from the homepage to the product experience. By integrating the prompt bar, we provide users with immediate access to the app, reducing friction and improving the likelihood of user interaction. The animation replacement offers a more dynamic and informative way to showcase the product’s capabilities, making it easier for users to understand and appreciate the value of Storytell.ai.Who We Built This For
This feature was primarily built for potential users visiting the Storytell.ai web app for the first time. The goal was to provide them with an engaging and intuitive experience that quickly demonstrates the app’s value and encourages them to start using it. By making the homepage more interactive and informative, we aim to attract and retain users who are looking for a powerful tool to turn data into insights.XLS → CSV Conversion
XLS → CSV Conversion
Summary
Our latest feature enables the conversion of XLS files into multiple CSV files, each corresponding to a tab in the original XLS file. This feature is designed to streamline data processing and enhance compatibility with various data analysis tools that prefer CSV format.Technical Details
The XLS → CSV conversion feature processes each tab within an XLS file independently, converting it into a separate CSV file. The conversion process involves several key steps:- File Parsing: The XLS file is parsed to identify individual tabs. Each tab is treated as a separate dataset.
- Data Extraction: Data from each tab is extracted, ensuring that both structured and semi-structured data are handled appropriately.
- Classification and Validation: The data is classified to determine its structure. This involves checking for consistent column counts and identifying header rows.
- Conversion: The extracted data is converted into CSV format. Special attention is given to handling non-tabular data and ensuring that data integrity is maintained.
- Error Handling: The system includes mechanisms to handle errors such as varied headers and unstructured data, with fallback strategies to ensure conversion success.
Explain It to Me Like I’m Five
Imagine you have a big book with lots of pages, and each page has a different story. Our new feature takes that book and turns each page into its own little book. So, if you have a book with five stories, you end up with five smaller books, each with one story. This makes it easier to read and share just the story you want.Specific Items Shipped
- Multi-Tab Conversion: Converts each tab in an XLS file into a separate CSV file. This allows for easier data management and analysis.
- Structured Data Handling: Ensures that data with consistent columns is accurately converted. This improves reliability for structured datasets.
- Semi-Structured Data Support: Implements fallback strategies for semi-structured data, enhancing flexibility in data conversion.
- Error Mitigation: Includes error handling for varied headers and unstructured data, reducing conversion failures.
- Validation and Testing: Comprehensive testing with various datasets to ensure robustness and accuracy.
The Problem We Solved with This Feature
We developed this feature to address the challenge of working with XLS files that contain multiple tabs. Many data analysis tools and workflows require data in CSV format, which is more universally compatible and easier to process. By converting XLS files into CSVs, we simplify data handling and improve accessibility for users who need to analyze or share data efficiently.Who We Built This For
This feature is particularly beneficial for data analysts, researchers, and business professionals who frequently work with large datasets in Excel format. It is designed to support use cases such as:- Data Analysis: Facilitating the import of data into analysis tools that prefer CSV format.
- Data Sharing: Simplifying the process of sharing specific datasets without the need to share entire Excel files.
- Data Management: Enhancing the organization and management of data by separating it into individual, manageable files.
CRUD Function for Collections
CRUD Function for Collections
Summary
The recently shipped feature enables users to perform various operations on Collections, specifically Create, Read, Update, and Delete (CRUD). This functionality gives users the flexibility to manage their Collections more effectively. They can create new Collections, rename existing ones, update them with new data, and delete unwanted Collections. Additionally, we’ve implemented a new API endpoint to facilitate the deletion of Collections directly.Explain it to me like I’m five
Imagine you have a toy box. This feature is like a special way to organize your toys. You can add new toys to the box, change the name of your toy box, take out toys when you don’t want them anymore, or even throw the whole toy box away. Also, there’s a button you can press to make sure you can throw away the toy box whenever you decide!Specific Items Shipped
-
Create Collection: Users can now create new Collections.
- This allows users to group related items easily, making organization easier.
-
Rename Collection: Existing Collections can be renamed.
- Users can change the name of a Collections to better reflect its contents or purpose.
-
Move Collection: Moving Collections helps users to organize their content more effectively.
- This feature provides flexibility for users to rearrange their Collections, ensuring that their organization systems remain current and intuitive.
-
Delete Collection: Added API endpoint for deleting Collections.
- Users can remove Collections they no longer need, ensuring the interface remains clutter-free and relevant.
The Problem We Solved with This Feature
We built this feature to address the challenges users faced in managing their Collections. Before this, users struggled with limited organization capabilities, leading to confusion as Collections grew. By providing a comprehensive set of CRUD functionalities, we empower users to keep their Collections tidy and easily accessible, which ultimately enhances their overall experience.Who We Built This For
This feature is designed for users who frequently manage Collections, such as project managers, researchers, and hobbyists. Specifically, it addresses those looking to streamline their organization of items, whether for projects, studies, or personal interests. By enhancing their ability to create, update, and delete Collections effortlessly, we improve their workflow and productivity.Address Non-Tabular Data in CSV Files
Address Non-Tabular Data in CSV Files
Summary
The newly shipped feature addresses the challenge of processing non-tabular data within CSV files. Unlike traditional CSV files that contain well-structured tabular data with consistent columns and headers, many files we receive lack these characteristics. This feature enables the system to handle such “report” type CSV files by leveraging a Language Learning Model (LLM) to generate data “chunks” effectively, ensuring no data points are lost in the process.Technical Details
The feature utilizes an LLM to parse and process CSV files that do not conform to standard tabular formats. The LLM is prompted to generate data chunks from the CSV content, even in the absence of headers or consistent columns. This involves modifying the prompt to ensure the LLM does not summarize or drop data points, which was a challenge in earlier implementations. Additionally, a “source” identifier is included in each chunk to enhance searchability and traceability of the data.Explain it to Me Like I’m Five
Imagine you have a messy box of toys instead of a neat row of blocks. Our new feature is like a special robot that helps organize these toys into groups, even if they don’t fit perfectly into rows. It makes sure every toy is in the right group and doesn’t lose any toys while doing so. Plus, it puts a little tag on each group so we can find them easily later.Specific Items Shipped
- LLM-Generated Data Chunks: The feature uses an LLM to create data chunks from non-tabular CSV files, ensuring all data points are captured.
- Prompt Modifications: Adjustments were made to the LLM prompts to prevent data summarization and ensure complete data retention.
- Source Inclusion in Chunks: Each data chunk now includes a “source” tag to improve searchability and data traceability.
- Regression Testing: Comprehensive testing was conducted using various datasets to validate the feature’s performance and reliability.
The Problem We Solved with This Feature
The primary problem addressed by this feature is the inability to process non-tabular CSV files effectively. Traditional methods failed due to the lack of headers and inconsistent columns, leading to incomplete data processing. By implementing this feature, we ensure that all data points are captured and organized, even in non-standard formats, which is crucial for accurate data analysis and decision-making.Who We Built This For
This feature was primarily built for data analysts and engineers who frequently work with CSV files that do not adhere to standard tabular formats. It is particularly useful for some organizations, where such files are common, and accurate data processing is essential for generating insights and reports.CSV Content Classification
CSV Content Classification
Summary
The newly shipped feature classifies CSV content as either “structured” or “unstructured.” This classification allows for the application of different processing strategies, ensuring that CSV files are handled appropriately based on their content type. Structured CSVs typically have a clear header row followed by data rows, while unstructured CSVs may not follow this format and require different handling.Technical Details
The feature employs a classification algorithm to analyze the content of CSV files. It inspects the first few rows to determine if they follow a structured format, characterized by a consistent header and data row pattern. If the pattern is not detected, the file is classified as unstructured. This classification is crucial for selecting the appropriate processing prompt, which optimizes data handling and ensures accuracy in data interpretation. The implementation is designed to be efficient, minimizing processing time and resource usage.Explain it to Me Like I’m Five
Imagine you have two kinds of boxes. One box has toys neatly organized with labels, and the other box has toys all jumbled up. This feature is like a helper that looks at each box and tells us if the toys are organized or not. If they are organized, we use one way to play with them, and if they are jumbled, we use a different way. This helps us make sure we always know how to handle the toys correctly.Specific Items Shipped
- Classification Algorithm: We built a smart system that looks at CSV files and decides if they are organized (structured) or not (unstructured).
- Efficient Processing: The feature is designed to quickly and accurately classify files without slowing down the system.
- Local Validation: We tested the feature with real data to make sure it works perfectly and doesn’t cause any problems.
The Problem We Solved with This Feature
In the real world, CSV files can vary significantly in format. Some are neatly structured, while others are not. This inconsistency can lead to processing errors and inefficiencies. By classifying CSV content, we ensure that each file is processed using the most suitable method, improving accuracy and efficiency in data handling.Who We Built This For
This feature is designed for data analysts and engineers who frequently work with CSV files. It addresses the need for accurate data processing in environments where CSV files may not always follow a standard structure. By automating the classification process, we reduce the manual effort required to handle diverse data formats, allowing users to focus on more critical tasks.Categorization for Comparative Queries in LLM Router
Categorization for Comparative Queries in LLM Router
Summary
We have enhanced our LLM (Large Language Model) router by adding a new feature that categorizes “comparative” queries. This improvement allows the router to better understand and process queries that involve comparisons, enhancing the model selection process. The router now returns a structured response to the prompt builder, which includes a list of categories identified by the LLM for the given prompt. This categorization helps in selecting the most appropriate model for processing the query.Technical details
The LLM router has been updated to include a categorization mechanism specifically for “comparative” queries. When a query is received, the router analyzes the content to determine if it involves any form of comparison. If a comparison is detected, the query is categorized accordingly. The router then returns a structured response to the prompt builder, which includes aPromptCategories list. This list contains the categories identified by the LLM, which are used to guide the model selection process. If the router cannot define a specific category, it assigns a generic category to ensure that the query is still processed effectively.Explain it to me like I’m five
Imagine you have a big box of crayons, and you want to pick the right color to draw a picture. Our new feature is like a helper that looks at your picture idea and tells you which crayon to use. If you’re drawing something that needs comparing, like “Is the sky bluer than the ocean?” our helper will know exactly which crayon to pick to make your picture look just right.Specific items shipped
- Comparative Query Categorization: We have implemented a system that identifies and categorizes queries involving comparisons. This helps in selecting the most suitable model for processing such queries.
- Structured Response to Prompt Builder: The router now returns a structured response that includes a
PromptCategorieslist. This list helps in guiding the model selection process by providing identified categories for the prompt. - Generic Category Assignment: In cases where a specific category cannot be determined, a generic category is assigned to ensure the query is processed effectively.
The problem we solved with this feature
This feature addresses the challenge of accurately processing queries that involve comparisons. Previously, the LLM router might not have effectively identified and categorized comparative queries, leading to suboptimal model selection. By introducing this categorization, we ensure that comparative queries are processed more accurately, improving the overall performance and reliability of our system.Who we built this for
This feature was primarily developed for users who frequently engage in queries that involve comparisons. It is particularly useful for applications where understanding and processing comparative language is crucial, such as data analysis, research, and decision-making tools. By enhancing the model selection process for these queries, we aim to provide a more accurate and efficient user experience.Web Scraper MVP
Web Scraper MVP
Summary
The Web scraper MVP is an initial release of our web scraping tool designed to extract data from websites efficiently. This feature leverages the Firecrawl API to crawl and scrape web pages, currently supporting the downloading of YouTube videos and their transcripts. The scraper is capable of handling multiple URLs, storing each page’s HTML as an asset within its respective Collection. While the current implementation focuses on downloading transcripts to prevent blocking the control plane, future updates will introduce job architecture for more extensive scraping capabilities.Technical Details
The Web scraper MVP utilizes several Python libraries, including theyoutube-transcript-api, to download YouTube videos and their transcripts. In its first generation, the scraper integrates the Firecrawl API to perform crawling and scraping tasks. Here’s a deeper look into its technical components:- Firecrawl Integration: Firecrawl is chosen for its ability to crawl entire websites rather than just single pages. It offers configuration options like maximum pages to crawl and crawl depth, allowing for controlled data extraction.
- Endpoint Management: Currently, the scraper operates under a single endpoint, which handles the downloading of transcripts to ensure that the control plane remains responsive. Future iterations will implement asynchronous processing to manage larger scraping tasks without hindering performance.
- Asset Storage: Each scraped page’s HTML is stored as an asset in the Collection from which it was added. This organized storage facilitates easy retrieval and management of scraped data.
- Scalability Considerations: To support scaling, the system plans to switch to Scrapfly for better credit cost efficiency and implement a robust job architecture using our existing queueing and job processing frameworks. Rate limiting and credit management are addressed to ensure sustainable usage of scraping resources.
- Challenges and Future Work: Upcoming enhancements include allowing users to specify multiple URLs for scraping, integrating anti-bot bypass strategies, and implementing proxy rotations to prevent IP blocking. These advancements aim to make the scraper more versatile and resilient against common web scraping obstacles.
Explain it to me like I’m five
Imagine you have a magic robot that can visit websites and copy down all the important information for you. The Web scraper MVP is like that robot. Right now, it can grab videos and their captions from YouTube and save the information neatly. It’s built to handle one website at a time, but soon it will be able to visit many websites at once without getting stuck. This helps us collect data quickly and keep everything organized.Specific Items Shipped
-
YouTube Transcript Downloading
Enabled the scraper to download transcripts from YouTube videos using Python libraries.
This feature allows users to automatically fetch and store the transcript of any YouTube video, facilitating content analysis and accessibility. -
Firecrawl API Integration
Implemented Firecrawl for efficient website crawling and scraping.
By leveraging Firecrawl, the scraper can navigate entire websites, respecting limits on the number of pages and crawl depth to manage resource usage effectively. -
Single Endpoint Operation
Configured the scraper to run under one endpoint to maintain control plane performance.
This design choice ensures that fetching transcripts does not interfere with other system operations, maintaining overall stability. -
Asset Storage System
Developed a system to store each scraped page’s HTML as an asset within its Collection.
This organized storage method allows for easy access and management of the scraped data, categorizing it based on the source Collection. -
Scalability Framework
Set the foundation for future scalability by planning job architecture and rate limiting.
Preparing for growth, this framework will support more extensive scraping tasks and manage usage effectively as the number of users and scraped URLs increases.
The Problem We Solved with This Feature
Before the Web scraper MVP, extracting data from websites, especially large ones, was time-consuming and resource-intensive. Manually downloading videos and transcripts from platforms like YouTube was inefficient and prone to errors. Our scraper automates this process, enabling rapid and accurate data collection. This matters because it saves significant time and resources for users who rely on up-to-date and comprehensive web data for analysis, research, or content creation.Who We Built This For
We developed the Web scraper MVP for engineers and researchers who need to gather large amounts of web data efficiently. Use cases include:- Content Aggregators: Automatically collecting and organizing video transcripts for content libraries.
- Data Analysts: Gathering web data for trend analysis and market research.
- Educational Institutions: Compiling resources and transcripts for academic projects and studies.
HIPAA certification
HIPAA certification
Use RAW Prompts for Suggestion Generation
Use RAW Prompts for Suggestion Generation
Summary
We have implemented a feature that stops sending transformed prompts to the Language Learning Model (LLM) when creating suggestions. Instead, the system now uses the raw prompts provided by the user. This change simplifies the suggestion process and enhances performance by reducing the complexity and processing time involved in generating suggestions.Technical details
Previously, when generating suggestions, the system injected additional system prompts into the user’s input, transforming the original prompt before sending it to the LLM. This transformation included predefined instructions and context that were not part of the user’s original request. While this approach provided a standardized context for the LLM, it introduced unnecessary complexity and increased the processing time, leading to slower suggestion generation.With the new feature, the system bypasses the transformation process and sends the user’s raw prompt directly to the LLM. This change reduces the payload size, minimizes processing overhead, and accelerates the response time for generating suggestions. By eliminating the additional system prompts, the LLM focuses solely on the user’s input, which streamlines the suggestion process and improves overall efficiency.Explain it to me like I’m five
Imagine you’re asking a friend for ideas on a drawing. Before, someone was adding extra instructions to your request, which made it take longer for your friend to come up with suggestions. Now, we let you ask your friend directly without any extra steps, so you get faster and simpler ideas for your drawing.Specific items shipped
- Direct Use of Raw Prompts: The system now sends the exact prompts provided by users to the LLM without any additional transformations or injected system prompts. This ensures that the suggestions are based solely on the user’s original input.
- Enhanced Performance: By removing the transformation layer, the time taken to process and generate suggestions has been significantly reduced, resulting in quicker response times and a more efficient user experience.
- Simplified Suggestion Pipeline: The elimination of system prompt injection streamlines the suggestion generation process, making it easier to maintain and reducing potential points of failure.
- Improved Accuracy of Suggestions: With the LLM receiving only the raw user input, the relevance and accuracy of the suggestions have improved, as there is less noise and fewer instructions that could potentially misguide the model.
The problem we solved with this feature
We identified that the process of transforming user prompts by injecting additional system prompts before sending them to the LLM was causing unnecessary complexity and delays in generating suggestions. This transformation not only slowed down the response time but also introduced potential inaccuracies in the suggestions by adding extraneous information. By switching to using raw prompts, we simplified the suggestion generation process, making it faster and more reliable. This improvement matters because it enhances the user experience by providing quicker and more relevant suggestions, which is crucial for maintaining user engagement and satisfaction.Who we built this for
We built this feature for our end-users who rely on quick and accurate suggestions to enhance their productivity and creativity. Specifically, users who interact with Storytell for content creation, brainstorming ideas, or seeking assistance in writing will benefit from faster and more relevant suggestions. By optimizing the suggestion generation process, we cater to professionals, writers, and creative individuals who need efficient tools to support their workflow and enhance their output quality.Refining Prompt Transformation for Friendlier Interactions
Refining Prompt Transformation for Friendlier Interactions
Summary
The primary objective of this update is to generate responses that are both faster and more user-centric. This feature enhances the generation of responses, making interactions more user-friendly and efficient. Its aim is to ensure that responses feel natural while also processing them more swiftly.Technical Details
For engineers, understanding the mechanics of this feature is crucial. Here’s a deeper dive:- System Context Settings: Adjustments have been made to the context settings to promote a more natural conversation flow, encouraging direct interaction with the user.
- Prompt Structure: The prompts have been redesigned to leverage reference materials, reducing the reliance on external training data unless necessary. This helps the system remain aligned with the specific context at hand.
- Diagnostics Integration: New diagnostic tools are implemented to track the accuracy and speed of prompt-response cycles, enabling ongoing improvements and ensuring reliability.
Explain It to Me Like I’m Five
Imagine writing a message to a friend. This feature helps the system respond in a way that’s easy to understand and quick, like getting a faster, friendlier text back from a friend. It’s designed to make conversations smoother and answers come quicker without any confusion.Specific Items Shipped
- More Friendly Responses: Improved Interaction - The new structure of prompts facilitates more conversational and natural interactions, smoothing out the dialogue between users and the system.
- Faster Responses: Enhanced Speed - With a more efficient processing system, prompts are turned into answers faster than before, reducing wait times.
- Diagnostics in Cloud Environment: Increased Reliability - By incorporating diagnostic tools, any discrepancies or issues can be rapidly identified and corrected, boosting the system’s overall dependability.
The Problem We Solved with This Feature
Previously, the system’s responses often seemed robotic and sometimes misaligned with what users were looking for. This feature addresses that by making responses more human-like and natural, enhancing the overall user experience and ensuring that interactions with the platform meet users’ expectations.Who We Built This For
This improvement benefits all Storytell users who interact through queries. By refining response quality and reducing wait times, users from different sectors, particularly those requiring prompt and clear interactions for their tasks, will experience a more efficient workflow.Exclude CSV Results from Search Routing
Exclude CSV Results from Search Routing
Summary
This feature enhances the routing logic by automatically excluding routes when the search results predominantly originate from CSV files. By implementing this, the system ensures that users receive the most relevant and diverse search results, improving overall user experience.Technical Details
The feature integrates a filtering mechanism within the existing search algorithm. It analyzes the source of search results and identifies the proportion of results derived from CSV files. If the CSV file results exceed a predefined threshold, the routing process bypasses these results, directing the search to alternative sources. This is achieved by modifying the routing API to include a validation step that checks the origin of each result and applies the exclusion criteria accordingly. Additionally, caching strategies are employed to minimize performance overhead during this verification process.Explain it to Me Like I’m Five
Imagine you’re looking for your favorite toy in a big toy store. Sometimes, most of the toys look the same and come from the same packaging (like CSV files). This feature helps the store staff make sure that when you search for a toy, you get a variety of options from different places, not just the ones that look alike. This way, you have a better chance of finding exactly what you want.Specific Items Shipped
- Routing Filter Module: Introduced a new module that scans search results to determine the origin of each result. This module evaluates whether the majority of search outcomes are from CSV files. If the condition is met, it triggers the exclusion process to remove these results from the routing path.
- Threshold Configuration Settings: Added configurable settings to define the percentage threshold for CSV file dominance in search results. Administrators can adjust the threshold based on varying needs, allowing flexibility in how strictly the routing exclusion is applied.
- Performance Optimization Techniques: Implemented caching mechanisms to store previously evaluated search results. These optimizations ensure that the additional filtering does not significantly impact the search performance, maintaining a seamless user experience.
- Enhanced Logging and Monitoring: Developed comprehensive logging features to track the filtering process and its impact on search routing. This facilitates easier troubleshooting and performance assessment, ensuring the feature operates as intended.
The Problem We Solved with this Feature
Previously, when users performed searches, a significant portion of the results came from CSV files, leading to repetitive and less diverse information being displayed. This repetition could frustrate users and reduce the perceived quality of the search functionality. By implementing the “Remove from Routing if the Search Results Contain Mostly Results from CSV Files” feature, we ensure that search results are more varied and relevant, enhancing user satisfaction and engagement.Who We Built This For
This feature is designed for users who rely on Storytell to access a wide range of data sources. Specifically:- Data Analysts: Who require diverse datasets for comprehensive analysis without being confined to CSV file limitations.
- Researchers: Seeking varied sources to support robust and multifaceted research outcomes.
- General Users: Looking for diverse information without redundancy, ensuring a more enriching search experience.
Improving Search System Visibility to Address Customer Issues
Improving Search System Visibility to Address Customer Issues
Summary
The Supportability(Search) feature enhances our search system by providing comprehensive visibility into tenant-specific assets and their embeddings. This improvement allows our team to monitor and understand customer issues more effectively by displaying detailed information about the assets and embeddings associated with each tenant.Technical Details
This feature integrates directly with our existing search and ingest services, enabling a seamless flow of information. A new user interface was designed, which offers real-time metrics reflecting the ingested assets and their corresponding embeddings. This is achieved through the backend’s connection to our databases.The feature employs optimized API endpoints that minimize performance overhead while ensuring that data retrieval is both efficient and accurate. It allows for queries that provide:- The total count of ingested assets
- The number of embeddings generated for those assets
- A breakdown of embeddings organized by asset for each tenant
Explain It to Me Like I’m Five
Imagine you have a big toy box filled with lots of toys, and your parents want to help you play with them. Sometimes it’s hard to know what toys you have and how they’re organized. The Supportability(Search) feature is like putting labels on each toy and organizing them into groups so you can easily see how many toys there are, what kinds they are, and how they are arranged. This way, you can find your favorite toys quickly and enjoy playing without any confusion!Specific Items Shipped
-
Enhanced Dashboard Interface: Introduced a new dashboard within the search service that displays real-time metrics on ingested assets and embeddings.
This dashboard provides a clear overview of the number of assets ingested and the embeddings generated for each tenant. Users can navigate to detailed views for specific organizations to see more granular data. -
Organizational Detail Views: Added detailed views for each organization, showing the number of assets and embeddings per asset.
These detail views allow engineers to drill down into specific tenants to better understand their data landscape. This granularity aids in troubleshooting and optimizing search performance for individual organizations. -
Optimized API Endpoints: Developed new API endpoints to fetch and serve asset and embedding data efficiently.
These optimized endpoints ensure that data retrieval is fast and reliable, minimizing latency and providing up-to-date information for the dashboard and detail views. -
Minimalistic User Interface: Maintained a clean and simple UI design for ease of use and quick navigation between services.
The minimalistic approach ensures that users can access the search and ingest services without unnecessary complexity, focusing on the functionality that matters most.
The Problem We Solved with This Feature
Before implementing Supportability(Search), our team lacked the necessary visibility into the search system’s inner workings, which made diagnosing and addressing customer issues related to search functionalities a challenge. This gap hindered our ability to understand which assets and embeddings were present for each tenant, leading to slower response times in troubleshooting and optimizing the search experience.Who We Built This For
Primarily for our engineering and support teams. These users require detailed visibility into the search system to monitor performance, diagnose issues, and optimize the search experience for our customers. Additionally, product managers benefit from these insights to make informed decisions about feature enhancements and resource allocation based on how different tenants utilize the search capabilities.- Story Tiles™ were added to SmartChat™
- Documentation is here
- Intelligent LLM Routing based on Quality vs. Price vs. Speed
- Documentation is here